It looks like you're using an Ad Blocker.
Please white-list or disable AboveTopSecret.com in your ad-blocking tool.
Thank you.
Some features of ATS will be disabled while you continue to use an ad-blocker.

Checksum discovered in DNA: More evidence of Simulation Theory?
page: 10share:
Originally posted by rhinoceros
Originally posted by Barcs
I believe this is a fallacy known as equivocation. Ironically enough we were discussing it in the other thread, but this is exactly that. The claim is that checksum was discovered. No it was not. It was discovered that cells can correct errors during replication. That is NOT the same thing as a file integrity check or even close to it. It's really just poor terminology and nothing more. Similarly it's the same thing when people compare information theory to DNA.
That was discovered a long time ago. In this study they claimed to have discovered another mechanism analogous to check-sums, but the claim is based on subjective interpretation of wrongly used data and is total BS.edit on 23-4-2012 by rhinoceros because: (no reason given)
I appreciate your interest in the subject and the discussions we have been having. But I am beginning to resent your constant referral to it as BS.
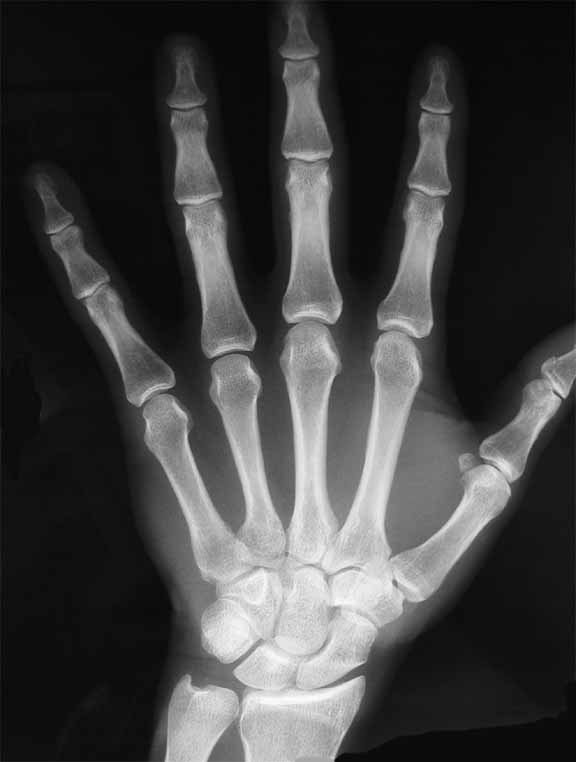
This picture is clear indication of the Fibonacci sequence. Bones created by DNA. These studies have been going on since '91. Papers have been published. If you want to call it BS then come up with your own paper to prove it.
Originally posted by FlySolo
I appreciate your interest in the subject and the discussions we have been having. But I am beginning to resent your constant referral to it as BS.
I already said why it's bull#:
1. The genome they used does not have 100% coverage. No published human genome has 100% coverage because our technology cannot yet read long enough segments to tell how long exactly very long repeat sequence regions are. Not only does this affect proportions of triplets, but it also changes frames.
2. Because every human genome will have completely different frames.
3. Because the triplet nature of DNA only applies to protein-coding regions. Elsewhere, looking at DNA in this regard makes no sense at all. They could have just as well counted in 4s or 5s or any number. It doesn't matter.
Unless you can disprove the points made here, the original claim is BS. It's as simple as that. Showing pictures of bones with vague references to Fibonacci does not make a difference.
Originally posted by rhinoceros
Originally posted by Barcs
I believe this is a fallacy known as equivocation. Ironically enough we were discussing it in the other thread, but this is exactly that. The claim is that checksum was discovered. No it was not. It was discovered that cells can correct errors during replication. That is NOT the same thing as a file integrity check or even close to it. It's really just poor terminology and nothing more. Similarly it's the same thing when people compare information theory to DNA.
That was discovered a long time ago. In this study they claimed to have discovered another mechanism analogous to check-sums, but the claim is based on subjective interpretation of wrongly used data and is total BS.edit on 23-4-2012 by rhinoceros because: (no reason given)
I think it is obvious in a lot of the posts, that we understand that there is certainly no computer based methodology at work in RNA and DNA. There is however, a correlation. The correlation states that there are some very fundamental concepts of error detection and correction that are so profound, useful and simple, that the principles behind them could perhaps be used in chemical processes as well, albeit very different in design.
Let's face it, DNA and RNA are such incredible molecules, and what they have been able to accomplish is staring back at these posts. Why would the concepts of error checking and correction be so foreign to something that is far more complex that we understand already?
Originally posted by rhinoceros
Unless you can disprove the points made here, the original claim is BS. It's as simple as that. Showing pictures of bones with vague references to Fibonacci does not make a difference.
I can't because I'm not qualified. But if you are qualified, then I would be happy to pass on your remarks to Perez. He has an email account linked to his site and I have a friend who is fluent in French. With your permission, I will translate your above statement and send it off to him and then make his response to you public.
Are you down with that?
reply to post by rhinoceros
I did not see were it was stated that the entire genome was really analyzed, Not only that, but that it was a human genome either. Perez counted the triplets in 1 genome, up to a billion. All of the triplet permutations returned of T,C,A,G. were analyzed and the running TREND returned by relating the T and A permutations (col1 and col3) with the C and G permutations (col2 and col4) of the ordered list of permutations showed a relationship with the data in the genome of 3-(phi/2). The chart shows a running list of the statistical permutations of 4 items taken 3 at a time, in empirical order.
Seems to me he has really sampled a huge dataset, and analyzing much more was not going to change the trend he noticed much at all. Who cares about the frames and whether they were protein-coding regions or not. It is purely a statistical analysis of all permutations ot T,C,A,G encountered in a running analysis of these triplets in the genome of what ever species he was looking at. I hold that if Perez was right about this, then there is no conflict with what FlySolo has indicated in the OP.
1. The genome they used does not have 100% coverage. No published human genome has 100% coverage because our technology cannot yet read long enough segments to tell how long exactly very long repeat sequence regions are. Not only does this affect proportions of triplets, but it also changes frames.
I did not see were it was stated that the entire genome was really analyzed, Not only that, but that it was a human genome either. Perez counted the triplets in 1 genome, up to a billion. All of the triplet permutations returned of T,C,A,G. were analyzed and the running TREND returned by relating the T and A permutations (col1 and col3) with the C and G permutations (col2 and col4) of the ordered list of permutations showed a relationship with the data in the genome of 3-(phi/2). The chart shows a running list of the statistical permutations of 4 items taken 3 at a time, in empirical order.
Seems to me he has really sampled a huge dataset, and analyzing much more was not going to change the trend he noticed much at all. Who cares about the frames and whether they were protein-coding regions or not. It is purely a statistical analysis of all permutations ot T,C,A,G encountered in a running analysis of these triplets in the genome of what ever species he was looking at. I hold that if Perez was right about this, then there is no conflict with what FlySolo has indicated in the OP.
edit on 24-4-2012 by charlyv because: spelling , where caught
Originally posted by charlyv
I did not see were it was stated that the entire genome was really analyzed, Not only that, but that it was a human genome either.
In the paper, Perez says...
We analyzed the entirety of the whole human genome from the 2003 “BUILD34” finalized release
Originally posted by charlyv
Perez counted the triplets in 1 genome, up to a billion. All of the triplet permutations returned of T,C,A,G. were analyzed ...
So the question has to be asked, why did he use TRIPLETS, as opposed to any other number.
Why sets of three? Why not sets of four? Or two? Or sets of nine?
Why that particular specific number?
Perez himself gives the answer, multiple times, but I quote here from the abstract...
The frequency of each of the 64 codons across the entire human genome is controlled by the codon’s position in the Universal Genetic Code table.
...we show that the entire human genome employs the well known universal genetic code table as a macro structural model...
... the Universal Genetic Code Table not only maps codons to amino acids, but serves as a global checksum matrix.
The reason he uses sets of three, is because he specifically wishes to use the amino acid coding table.
but as I said a few days ago the sets of three that he has arrived at has absolutely nothing whatsoever to do with the amino acid coding table.
There is no connection whatsoever with his work, and the Universal Genetic Code Table that maps codons to amino acids.
I genuinely believe, after reading a bit more of the paper, that Perez himself doesnt understand this. I think he genuinely thinks that he does indeed have amino acid codon triplets, because of the terminology he uses, and always using the word "codon" to describe his triplets without ever making the correct distinction between the two. (When really he should have used a different word altogether - I suggest "threesomes" )
As I said previously, a copy of the original paper can be found here.
Originally posted by charlyv
I think it is obvious in a lot of the posts, that we understand that there is certainly no computer based methodology at work in RNA and DNA. There is however, a correlation. The correlation states that there are some very fundamental concepts of error detection and correction that are so profound, useful and simple, that the principles behind them could perhaps be used in chemical processes as well, albeit very different in design.
Correlation does not imply causation. The derived correlation is due to misuse of data, and the part about check-sum is just a guess.
reply to post by FlySolo
Good thread. Just like anything in existence, there's a system that enables the human body to function in a logical manner.
And further proof of the existence of God.
Good thread. Just like anything in existence, there's a system that enables the human body to function in a logical manner.
And further proof of the existence of God.
Skipped most of the thread as my time is limited...
I understand that the structure of the universe is self-similar and scale-invariant from my study of Chaos/Sync/Complexity, that the universe is likened to the machine of the era, yesterday's clockwork is today's quantum computer.
I just read the book PHYSICS ON THE FRINGE by Margaret Wertheim. One of the things she discusses is the culture of insider vs. outsider physics.
It seems to me that finding error correction codes in String Theory and Biology is an example of the connections made as we are drawn closer to the Kurzweilian Singularity. These patterns cannot be regarded as arbitrary but expected. The resistance to this comes from insider physicists (academic gate keepers and specialist calculators) because they are not equipped to deal with the requisite interdisciplinary methodology needed to get a truly unified theory - the one that accounts for otherwise metaphysical phenomena such as consciousness.
Standard/Classical physics is still at odds with Quantum/Aether physics, and its only because physics progresses one funeral or one crank at a time.
For example, as an outsider I can say with certainty that:
The Tree of Life IS an Adinkras, and it serves the same purpose - It geometrically encodes/contains the instruction set for the evolution of creation.
So if they are similar or analogs, how do we go about assigning physics terms/values to what the old school Jews could only describe as angels or attributes? Association. The nodes = sephiroth. We could equate Kether with Zero Point Field, the left column would be Bosons, the right column Fermions, the middle column would be force carriers. The upper sephiroth would be hyperspace, the lower, local space. There are ways of deriving binary determinism here, in the very behavior of particles...
I have no problem saying HEAVEN = HYPERSPACE:
The Seraphim = angels that stand on either side of God and are concealed by 6 wings
Calabi Yau Spaces = manifolds that mirror pair a Hodge Star and are enfolded by 6 real dimensions
What physicist is going to risk his career drawing such conclusions?
That's why we have dudes like me and Nassim:
www.youtube.com...
I understand that the structure of the universe is self-similar and scale-invariant from my study of Chaos/Sync/Complexity, that the universe is likened to the machine of the era, yesterday's clockwork is today's quantum computer.
I just read the book PHYSICS ON THE FRINGE by Margaret Wertheim. One of the things she discusses is the culture of insider vs. outsider physics.
It seems to me that finding error correction codes in String Theory and Biology is an example of the connections made as we are drawn closer to the Kurzweilian Singularity. These patterns cannot be regarded as arbitrary but expected. The resistance to this comes from insider physicists (academic gate keepers and specialist calculators) because they are not equipped to deal with the requisite interdisciplinary methodology needed to get a truly unified theory - the one that accounts for otherwise metaphysical phenomena such as consciousness.
Standard/Classical physics is still at odds with Quantum/Aether physics, and its only because physics progresses one funeral or one crank at a time.
For example, as an outsider I can say with certainty that:
The Tree of Life IS an Adinkras, and it serves the same purpose - It geometrically encodes/contains the instruction set for the evolution of creation.
So if they are similar or analogs, how do we go about assigning physics terms/values to what the old school Jews could only describe as angels or attributes? Association. The nodes = sephiroth. We could equate Kether with Zero Point Field, the left column would be Bosons, the right column Fermions, the middle column would be force carriers. The upper sephiroth would be hyperspace, the lower, local space. There are ways of deriving binary determinism here, in the very behavior of particles...
I have no problem saying HEAVEN = HYPERSPACE:
The Seraphim = angels that stand on either side of God and are concealed by 6 wings
Calabi Yau Spaces = manifolds that mirror pair a Hodge Star and are enfolded by 6 real dimensions
What physicist is going to risk his career drawing such conclusions?
That's why we have dudes like me and Nassim:
www.youtube.com...
edit on 24-4-2012 by Kalki11 because: embed
edit on 24-4-2012 by Kalki11 because: embed did not work
reply to post by alfa1
Thanks for the correction in the fact that it was indeed a human genome being measured.
There are certainly some aspects of the distribution analysis he conducted that do not jive with what biologists hold as samples that would be in any way valid. I took it that the actual structures/places being sampled were not as important to his method as just the plain distribution itself of the permutations of the 4 amino acids in general. Additionally, I took the reason that he chose triplets, as the triplet permutations of all the other amino acids given a base. Eg.. all the remaining permutions aftet T, ... after C.... after G.... after A.... So perhaps not steeped in the kind of analysis a biologist would be interested in, still, the outcome of what he did look at had the 3-(Phi/2) relationship, and that is still interesting. It was not like he tried to manipulate the samples to meet that goal, but just did a straight read through the genome.
Thanks for the correction in the fact that it was indeed a human genome being measured.
There are certainly some aspects of the distribution analysis he conducted that do not jive with what biologists hold as samples that would be in any way valid. I took it that the actual structures/places being sampled were not as important to his method as just the plain distribution itself of the permutations of the 4 amino acids in general. Additionally, I took the reason that he chose triplets, as the triplet permutations of all the other amino acids given a base. Eg.. all the remaining permutions aftet T, ... after C.... after G.... after A.... So perhaps not steeped in the kind of analysis a biologist would be interested in, still, the outcome of what he did look at had the 3-(Phi/2) relationship, and that is still interesting. It was not like he tried to manipulate the samples to meet that goal, but just did a straight read through the genome.
Originally posted by rhinoceros
Originally posted by charlyv
I think it is obvious in a lot of the posts, that we understand that there is certainly no computer based methodology at work in RNA and DNA. There is however, a correlation. The correlation states that there are some very fundamental concepts of error detection and correction that are so profound, useful and simple, that the principles behind them could perhaps be used in chemical processes as well, albeit very different in design.
Correlation does not imply causation. The derived correlation is due to misuse of data, and the part about check-sum is just a guess.
Understand that but given the enormous complexity of DNA/RNA there has to be embedded process control to avoid and correct errors. Nothing can possibly be perfect. The use/misuse of data here seems to be relative to what certain people believe is understood about DNA, and the incredible amount we know nothing about.
Originally posted by charlyv
Understand that but given the enormous complexity of DNA/RNA there has to be embedded process control to avoid and correct errors. Nothing can possibly be perfect. The use/misuse of data here seems to be relative to what certain people believe is understood about DNA, and the incredible amount we know nothing about.
There are at least two kinds of error checking mechanisms. One happens by DNA polymerase while it replicates DNA, and another happens shortly after. These are both well understood processes, and are related to cues detected from incorrect base-pairings between the two strands. Perez argues that there is another completely different kind of mechanism, although he does not propose any way how it could possibly function. In fact, his only argument is that some ratios are observed and from this he jumps to the wild conclusion that there must be a check-sum thing going on. I'm fairly certain that those ratios he observed are an artifact of his methodology.
edit on 24-4-2012 by rhinoceros because: (no reason given)
This would explain why we age. The cell checksum error rate increases over time after the age of 25. The volume of good cells becomes reduced because
too many cells have to be terminated due to errors. Everything in the body becomes thinned out and weak. For example the epidermis becomes thinner and
we shrink due to a loss of bone density. When there's a malfunction in the checksum termination protocol the defective cell is allowed to live and it
becomes cancer.
Ok, firstly apologies if this has already been mentioned elsewhere, I did a quick search which showed up nothing.
Secondly this is a bit of a tangent from the original post, but still on topic. I don't have enough posts to create a new thread.
I first saw mention of this a few days ago, but I struggled to find a reputable source, and I refuse to quote the daily mail.
There is talk that efforts to simulate small parts of the universe may in fact provide insight in to how we may detect if our own universe is a simulation.
I don't pretend to understand all of the physics, or theories involved, but here is more information:
www.technologyreview.com...
Secondly this is a bit of a tangent from the original post, but still on topic. I don't have enough posts to create a new thread.
I first saw mention of this a few days ago, but I struggled to find a reputable source, and I refuse to quote the daily mail.
There is talk that efforts to simulate small parts of the universe may in fact provide insight in to how we may detect if our own universe is a simulation.
I don't pretend to understand all of the physics, or theories involved, but here is more information:
www.technologyreview.com...
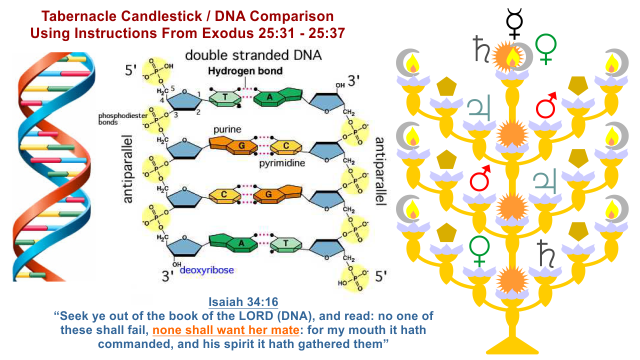
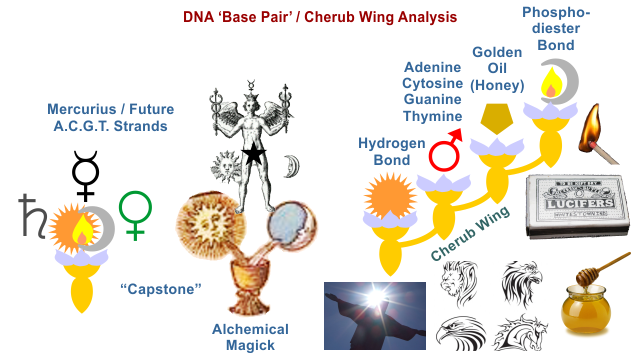
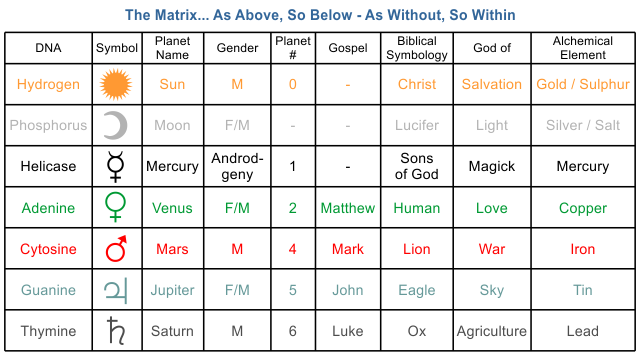
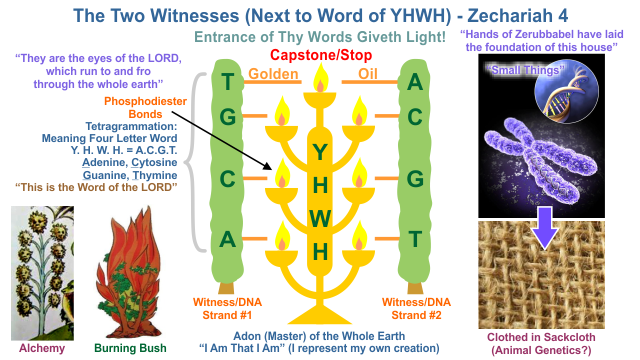
Originally posted by FlySolo
reply to post by charlyv
This video of how the DNA copies itself sums it up
Your video is like an RNA transcription combined with reproduction, as when the video is finished you are presented with nine or so other videos on the same topic. These videos seem as interesting and educational as the video presented. So wrapped up in your video are the potentialities of all videos related to the subject, just as the first DNA strand multiplied and became all life on earth.
Originally posted by lostinspace
This would explain why we age. The cell checksum error rate increases over time after the age of 25. The volume of good cells becomes reduced because too many cells have to be terminated due to errors. Everything in the body becomes thinned out and weak. For example the epidermis becomes thinner and we shrink due to a loss of bone density. When there's a malfunction in the checksum termination protocol the defective cell is allowed to live and it becomes cancer.
It's also evidence against any type of intelligent design. It we were created by this powerful creator why would the error checking process get worse year after year. Doesn't sound very intelligent or powerful to me and directly refutes the idea of computer simulation. Sloppy programming if so, and it's fixable... but it has not been fixed?? All powerful creator / computer programmer? I think not.
edit on 8-1-2013 by Barcs because:
(no reason given)
Originally posted by FlySolo
Originally posted by MichaelYoung
Sorry, but checksums in DNA are hardly evidence that the whole universe is a simulation.
It's far more likely that we were genetically engineered by aliens, IMO.
That's the sequel. Considering checksums aren't a natural occurrence, perhaps everything has been engineerededit on 20-4-2012 by FlySolo because: (no reason given)
But why would it be GOD, right?? Naaaa ALIENS..........
new topics
-
Well this is Awkward .....
Mainstream News: 30 minutes ago -
Kurakhove officially falls. Russia takes control of major logistics hub city in the southeast.
World War Three: 1 hours ago -
Liberal Madness and the Constitution of the United States
US Political Madness: 7 hours ago
top topics
-
New York Governor signs Climate Law that Fines Fossil Fuel Companies
US Political Madness: 14 hours ago, 17 flags -
Liberal Madness and the Constitution of the United States
US Political Madness: 7 hours ago, 8 flags -
Kurakhove officially falls. Russia takes control of major logistics hub city in the southeast.
World War Three: 1 hours ago, 5 flags -
Well this is Awkward .....
Mainstream News: 30 minutes ago, 5 flags
active topics
-
Plane Crash Today --Azerbaijanian E190 passenger jet
Mainstream News • 40 • : GENERAL EYES -
New York Governor signs Climate Law that Fines Fossil Fuel Companies
US Political Madness • 23 • : GENERAL EYES -
Trump says ownership of Greenland 'is an absolute necessity'
Other Current Events • 56 • : cherokeetroy -
UK Borders are NOT Secure!
Social Issues and Civil Unrest • 16 • : angelchemuel -
Well this is Awkward .....
Mainstream News • 0 • : asabuvsobelow -
Elon Musk futurist?
Dreams & Predictions • 17 • : GENERAL EYES -
Kurakhove officially falls. Russia takes control of major logistics hub city in the southeast.
World War Three • 1 • : xuenchen -
Cold Blooded Killers on Christmas!! GRRRRrrr!!
Pets • 14 • : rickymouse -
Post A Funny (T&C Friendly) Pic Part IV: The LOL awakens!
General Chit Chat • 7962 • : underpass61 -
Panamanian President-“every square meter” of the Panama Canal belongs to Panama.
New World Order • 48 • : fringeofthefringe