It looks like you're using an Ad Blocker.
Please white-list or disable AboveTopSecret.com in your ad-blocking tool.
Thank you.
Some features of ATS will be disabled while you continue to use an ad-blocker.

The 154 GB NARA Blue Book Archive
page: 2share:
originally posted by: Shadoefax
Great job, but I have to ask. Why is the archive so large? If it consists of 129,000 pages and is 154 GB in size, that works out to about 837 KB per page. I realize that the pages are scanned images, but what format? If they are in a non-compressed format (like .tif or .bmp) surely they can be re-sampled as .jpg or .png and reduced in size ten to 100-fold. It would be a lot easier to download 1.5 GB than 154.
Good question! There are actually 130,239 pages. The JPGs are an exact mirror of what you'll get from the Fold3-NARA Archive. The default resolution of each scan is approximately 3488 x 4364.
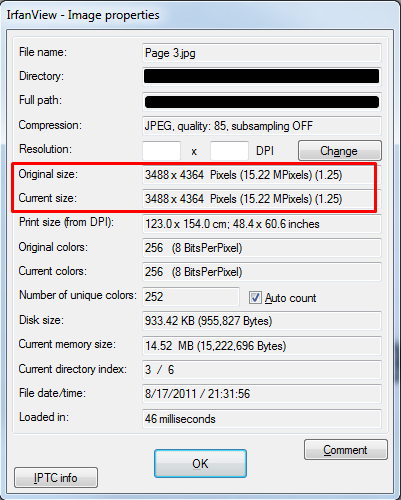
We wanted to keep the images in their native format to make it easier for optical character recognition to pick out harder to detect words and characters. Otherwise we'd be left with something less optimal like:
www.bluebookarchive.org...
Click "Page Text" to see what I'm getting at.
edit on 2014-9-14 by Xtraeme because: (no reason given)
a reply to: Xtraeme
Yes, it does make sense to keep the images in the highest resolution for OCR processing. But I was thinking more about the average Joe who just wants to download the archive to peruse.
A utility like ffmpeg could be run in an unattended batch file to do the reducing in short order.
Yes, it does make sense to keep the images in the highest resolution for OCR processing. But I was thinking more about the average Joe who just wants to download the archive to peruse.
A utility like ffmpeg could be run in an unattended batch file to do the reducing in short order.
Interesting job there. My past experience reading OCR'd books (project Gutenburg) seems to show the process is still anything but ideal. That text
data is going to need some proofreading in comparison to the scanned documents if it's to be of much good. Also formatting can be funny at times,
page breaks, or whatever OCR tends to do that can be annoying in a flowing layout. Yet having text files will be a good start, even if it falls short
of what may be an ideal relational database format. Should also be a lot smaller than the uncompressed images, which is what I'm guessing adds up to
154GB.
Also if enough people go through it, it might be interesting if it pares down any with redundant entries. Knowing how forms are handled, copied, and filed, etc. at any bureaucratic organization I wouldn't be surprised if there were two or three of the same thing in some cases. Also there may be some differences between them or addenums to a same case, which might be interesting to look at.
Also if enough people go through it, it might be interesting if it pares down any with redundant entries. Knowing how forms are handled, copied, and filed, etc. at any bureaucratic organization I wouldn't be surprised if there were two or three of the same thing in some cases. Also there may be some differences between them or addenums to a same case, which might be interesting to look at.
Great work! That's a lot of gigs to download, but I like a challenge!
One of the first files I cracked open, 9668679, describes a flying rainbow crate! What is the deal with UFO's and rainbow assortments of lights?
Good stuff, thank you for all the hard work. Releasing this out into the Internets to crowd-source further progress is probably a very good idea.
One of the first files I cracked open, 9668679, describes a flying rainbow crate! What is the deal with UFO's and rainbow assortments of lights?
Good stuff, thank you for all the hard work. Releasing this out into the Internets to crowd-source further progress is probably a very good idea.
To check the integrity of the data, here is a directory list and a SHA1
of all of the files. Windows users can use fsum (ex. fsum -jf -c footnote.com-sha1.txt). Mac and linux
users should be able to use sha1sum or 'openssl sha1 footnote.com-sha1.txt' to accomplish the same effect.
Blockchain proof of date/timestamp: www.proofofexistence.com...
Registered: 2014-09-15 05:25:33
Transaction broadcast timestamp: 2014-09-15 06:26:41
Anyone can verify the time of the 7z themselves by dragging and dropping it into: www.proofofexistence.com...
For the more technically savvy who would prefer to verify the file by hand:
Tx Hash: blockexplorer.com...
OP_RETURN 444f4350524f4f46d684c754ff4117657d51aa93e4c8bbc89f5a6a6a9d7d57fdbd63cf0ed72929b7
DOCPROOF: 444f4350524f4f46
SHA256: d684c754ff4117657d51aa93e4c8bbc89f5a6a6a9d7d57fdbd63cf0ed72929b7
Blockchain proof of date/timestamp: www.proofofexistence.com...
Registered: 2014-09-15 05:25:33
Transaction broadcast timestamp: 2014-09-15 06:26:41
Anyone can verify the time of the 7z themselves by dragging and dropping it into: www.proofofexistence.com...
For the more technically savvy who would prefer to verify the file by hand:
Tx Hash: blockexplorer.com...
OP_RETURN 444f4350524f4f46d684c754ff4117657d51aa93e4c8bbc89f5a6a6a9d7d57fdbd63cf0ed72929b7
DOCPROOF: 444f4350524f4f46
SHA256: d684c754ff4117657d51aa93e4c8bbc89f5a6a6a9d7d57fdbd63cf0ed72929b7
edit on 2014-9-15 by Xtraeme because: (no reason given)
originally posted by: pauljs75
Interesting job there. My past experience reading OCR'd books (project Gutenburg) seems to show the process is still anything but ideal. That text data is going to need some proofreading in comparison to the scanned documents if it's to be of much good.
I agree, I was proofreader on Project Gutenberg some years ago, and even with two proofreaders having worked on a text is not that rare to find some errors.
Also formatting can be funny at times, page breaks, or whatever OCR tends to do that can be annoying in a flowing layout.
That's why Project Gutenberg started by using simple text, with no formatting. Also, that's the only thing a database needs.
It's a lot of work, but I think there's enough man power on ATS to simply transpose the pages onto word documents, which can then be easily made
into pdfs. Having to babysit an OCR system, imho, would just make extra work. I don't even have to look at where I'm typing, when copying something.
OCR system would be great, to then be able to make a MySQL database and all data searchable... queries etc...
This is great work. Kudos.
If an actual database is the end goal here, has anyone actually drafted up a data model?
I'm curious as to what types of data people would like to extrapolate out of said database.
Location? Time of event? People involved? Radiation emissions? Physical characteristics?
Ultimately, I would think the usefulness of such a trove of data would lie in statistical analysis.
Just to be able to show, without a doubt, statistical consistency of a certain type of reported sighting would amazing.
Food for thought.
If an actual database is the end goal here, has anyone actually drafted up a data model?
I'm curious as to what types of data people would like to extrapolate out of said database.
Location? Time of event? People involved? Radiation emissions? Physical characteristics?
Ultimately, I would think the usefulness of such a trove of data would lie in statistical analysis.
Just to be able to show, without a doubt, statistical consistency of a certain type of reported sighting would amazing.
Food for thought.
So next step would be OCR, is there any good open source OCR out there these days?
So Xtraeme,
have you had any knocks on your door from guys wearing black suits? For that matter, anything weird happen to you since you started/finished this?
have you had any knocks on your door from guys wearing black suits? For that matter, anything weird happen to you since you started/finished this?
Hello, and great work on getting this dataset. I run TheBlackVault.com and love to archive these documents. Although I know how to torrent, and think
it's a great way to disseminate this, I am interested in hosting the entire collection on my server.
I'd love to work with you on maybe seeing up an FTP server, and asking if you'd be interested in uploading. I can start my Torrent program to download that way, but it sounds like there aren't too many seeders (if at all) and probably not many who could seed a dataset this large.
I hope the moderators don't mind me posting this, but would like to help.
I will watch this thread the best I can, and also invite you to email me at [email protected].
John Greenewald
I'd love to work with you on maybe seeing up an FTP server, and asking if you'd be interested in uploading. I can start my Torrent program to download that way, but it sounds like there aren't too many seeders (if at all) and probably not many who could seed a dataset this large.
I hope the moderators don't mind me posting this, but would like to help.
I will watch this thread the best I can, and also invite you to email me at [email protected].
John Greenewald
Thank for posting ! reminds me of another Archive someone posted with a account on Share 4 a Claimed MK Ultra Victim that had a whole mess load
of Conspiracy Archives for all ATS to See
Massive Cache of PDF's (Conspiracy related)
The Forbidden Library & Vault
Through his research as a truth seeker and whistle blower, Aaron McCollum has amassed a huge collection of PDF's pertaining to pretty much all of the topics covered here on ATS. Ranging from ebooks to government and military documentation.
www.abovetopsecret.com...
Seems like the Account is gone !
Massive Cache of PDF's (Conspiracy related)
The Forbidden Library & Vault
Through his research as a truth seeker and whistle blower, Aaron McCollum has amassed a huge collection of PDF's pertaining to pretty much all of the topics covered here on ATS. Ranging from ebooks to government and military documentation.
www.abovetopsecret.com...
edit on 15-9-2014 by Wolfenz because: (no reason given)
Seems like the Account is gone !
edit on 15-9-2014 by Wolfenz because: (no reason given)
new topics
-
Speaking of Pandemics
General Conspiracies: 1 hours ago -
Stuck Farmer And His Queue Jumping Spawn
Rant: 1 hours ago -
Paradox of Progress
Ancient & Lost Civilizations: 9 hours ago
top topics
-
Joe Biden gives the USA's Highest Civilian Honor Award to Hillary Clinton and George Soros.
US Political Madness: 12 hours ago, 13 flags -
Winter Storm
Fragile Earth: 12 hours ago, 7 flags -
A great artist and storyteller, for kids of all ages
General Entertainment: 15 hours ago, 6 flags -
Paradox of Progress
Ancient & Lost Civilizations: 9 hours ago, 6 flags -
Biden Face Planted Somewhere
Politicians & People: 14 hours ago, 5 flags -
Stuck Farmer And His Queue Jumping Spawn
Rant: 1 hours ago, 2 flags -
Speaking of Pandemics
General Conspiracies: 1 hours ago, 0 flags
active topics
-
Speaking of Pandemics
General Conspiracies • 3 • : billxam1 -
What Is 'Quad Demic'? Mask Mandate Returns In These US States
Diseases and Pandemics • 31 • : billxam1 -
Stuck Farmer And His Queue Jumping Spawn
Rant • 2 • : billxam1 -
The theory that COVID-19 originated in China takes a body blow.
Diseases and Pandemics • 57 • : Lazy88 -
FIEND SLASHED: Sara Sharif’s killer dad ‘has neck & face sliced open with jagged tuna tin lid
Mainstream News • 21 • : Asktheanimals -
Post A Funny (T&C Friendly) Pic Part IV: The LOL awakens!
General Chit Chat • 7989 • : Flyingclaydisk -
A great artist and storyteller, for kids of all ages
General Entertainment • 2 • : Asktheanimals -
Nigel Farage's New Year Message.
Politicians & People • 21 • : gortex -
The Future of fashion .
Social Issues and Civil Unrest • 20 • : Flyingclaydisk -
NJ Drones tied to Tesla explosion at Trump Las vegas
General Conspiracies • 46 • : Flyingclaydisk