It looks like you're using an Ad Blocker.
Please white-list or disable AboveTopSecret.com in your ad-blocking tool.
Thank you.
Some features of ATS will be disabled while you continue to use an ad-blocker.

Huge UFO Database in DOS - Someone's labour of love, can it be saved?
page: 9share:
originally posted by: EvillerBob
originally posted by: charlyv
I was a forensics C programmer years ago and helped to back engineer "proprietary" databases that big companies were actually using, without standards or documentation.
I've always strongly recommended that people never comment their code, it takes all the fun out of things for future programmers...
One thing for sure, it created a lot of contracts.
Ok, let's start getting... funky. Yes, it's SQL time.
At the moment I'm working with a single table for the data and some lookup tables for references/terrain/etc. I'm not entirely happy with this.
My first proposal is to split the record into two logical sets. You might think of this as "the specific incident" and "the case note about the incident".
The first table contains the "factual" evidence: time, date, location, elevation, etc. This uniquely identifies the specific incident and I will refer to this throughout as the "incident" table. I use the term "factual" while remaining fully aware of the limitations of the word given the subject matter and the reliance on eyewitness testimony. Play nicely
The second table contains the analysis: LH's description, the attributes, the strangeness/credibility rating, etc. I refer to this as the "case note" table.
I'd almost consider this to be the first normal form (1NF) for the database, as the incident and case note are, philosophically at least, two slightly different sets of data. I say "almost" as in my version I'm storing the location as both DMS and Decimal Degrees. For... reasons. However, I'll gloss over this with some handwaving about them conceptually representing "different bits of data" and pretend that the table is now 1NF compliant.
There is also a question over duplicating the location - the lat/long should represent the same information (albeit more specific) as the continent/country/local region codes. However, I look at these as regional groupings rather than a specific location, in order to avoid having to think too deeply about this issue. They certainly provide a more efficient search capability because it would be a mind-numbing waste of processor cycles (not to mention simply ridiculous) to work out which of the 18,000+ lat/longs fell inside a particular state or region, every time you wanted to search by state. That's my justification and I'm sticking with it and I will continue to hold on to the increasingly tenuous claim of 1NF compliance.
It also creates an additional benefit - growth and depth. It becomes easier to connect multiple case notes to the same incident. As well as returning the LH case note, you might have an IK casenote for a particularly interesting or contentious incident.
What about the second normal form (2NF)? There is little to do in this respect as much of the information that could be devolved to separate lookup tables has already been so devolved. An exception would be the "local region" three letter code, which really should not be user-entered text. This should also be devolved to another lookup table. To my mind, it makes no sense to separate out any other columns.
2NF goes a bit further, however. We need to look at the foreign keys linking the tables. For the look up tables we are using the id (or "code" if you prefer) currently used by the database. For terrain and continent this does not need further work. For the country code, we run into a problem. The country code is not unique - it is an index number within the continent subset. So, the country code needs to be addressed.
I would suggest reordering the country codes into a single set with contiguous numbering. As the data is inserted, the existing continent/country code system can be programmatically updated to meet the new criteria. "GBI", for example, would no longer be 3/0 (as in continent subset 3, index 0) and become 48.
I would extend this with a parentid that references the continent table, to allow the database to only present country options that match the selected continent. It could also allow a country to be selected and the appropriate continent to be populated automatically. A similar approach would be extended to my personal bugbear discussed earlier in the thread, the local region codes - these roughly equate to "states" for the US, "counties" for the UK, etc.
You might be wondering what continent/country/local codes could be used. I'd refer you to my previous post discussing the potential for reverse-geocoding to tackle this problem and bring the data into ISO compliance.
At this stage, I'd say we're close enough to 2NF to call it good. Shall we go for 3NF? No. I mean, we could, and there's an argument that it's almost 3NF as it stands (especially if decimal degrees are computed on the fly - which is entirely viable as we're pulled the DMS from the database in most cases and may not even use the decimal degrees) but I'm drawing the line at 2NF so I don't feel guilty about doing a bit of fiddling. Although I haven't checked the mathematics, I suspect that a "search within radius" function will probably work better with DD so I would like to have it stored in a column rather than calculate it 18,000+ times every time we run a search that is already going to be computation-heavy. This extra column would violate 3NF (remembering that we're ignoring the fact that we're already technically violating 1NF) as we're also storing the DMS as separate integers to ensure accuracy against the original record.
What about the second table? Text lives in that table quite happily. Reference is already a... well, reference, or more specifically a foreign key to another table. "Pinpoint" as I call it (or "page number" if you prefer) is a bit more difficult. It technically relies on the reference field to give it meaning, which isn't exactly 3NF compliant. My solution for this would be to create a single column in the table that holds a foreign key for the "pinpoint" table. The pinpoint table would hold the pinpoint and, as a pinpoint will only ever refer to one source, a foreign key for the "reference" table. This enables our casenote table to pull up the pinpoint, which can drag the appropriate reference in with it. It's also more compliant with 1-3NF, which I'm still pretending is the goal.
There is one possible elephant left in the room. Record ID. This makes the most logical primary key for the whole shebang. I was toying with the idea of having a system-unique id as an autoincrementing primary id and make a seperate record id. This rather goes against the spirit of avoiding duplication and there doesn't seem to be a compelling reason for doing so, so I'll continue with this as the primary key unless a good reason to reconsider arises. I should point out that the records don't actually have an id - the id is computed based on the pointer position within the file. If you jump 5 * 102bytes, you're at record #5. This is why I had initially considered creating a canonical reference and a system-specific reference.
Let's start making some tables using pseudo-sql... however it will be in the next post as I appear to have hit a character limit halfway through laying out the first table
At the moment I'm working with a single table for the data and some lookup tables for references/terrain/etc. I'm not entirely happy with this.
My first proposal is to split the record into two logical sets. You might think of this as "the specific incident" and "the case note about the incident".
The first table contains the "factual" evidence: time, date, location, elevation, etc. This uniquely identifies the specific incident and I will refer to this throughout as the "incident" table. I use the term "factual" while remaining fully aware of the limitations of the word given the subject matter and the reliance on eyewitness testimony. Play nicely
The second table contains the analysis: LH's description, the attributes, the strangeness/credibility rating, etc. I refer to this as the "case note" table.
I'd almost consider this to be the first normal form (1NF) for the database, as the incident and case note are, philosophically at least, two slightly different sets of data. I say "almost" as in my version I'm storing the location as both DMS and Decimal Degrees. For... reasons. However, I'll gloss over this with some handwaving about them conceptually representing "different bits of data" and pretend that the table is now 1NF compliant.
There is also a question over duplicating the location - the lat/long should represent the same information (albeit more specific) as the continent/country/local region codes. However, I look at these as regional groupings rather than a specific location, in order to avoid having to think too deeply about this issue. They certainly provide a more efficient search capability because it would be a mind-numbing waste of processor cycles (not to mention simply ridiculous) to work out which of the 18,000+ lat/longs fell inside a particular state or region, every time you wanted to search by state. That's my justification and I'm sticking with it and I will continue to hold on to the increasingly tenuous claim of 1NF compliance.
It also creates an additional benefit - growth and depth. It becomes easier to connect multiple case notes to the same incident. As well as returning the LH case note, you might have an IK casenote for a particularly interesting or contentious incident.
What about the second normal form (2NF)? There is little to do in this respect as much of the information that could be devolved to separate lookup tables has already been so devolved. An exception would be the "local region" three letter code, which really should not be user-entered text. This should also be devolved to another lookup table. To my mind, it makes no sense to separate out any other columns.
2NF goes a bit further, however. We need to look at the foreign keys linking the tables. For the look up tables we are using the id (or "code" if you prefer) currently used by the database. For terrain and continent this does not need further work. For the country code, we run into a problem. The country code is not unique - it is an index number within the continent subset. So, the country code needs to be addressed.
I would suggest reordering the country codes into a single set with contiguous numbering. As the data is inserted, the existing continent/country code system can be programmatically updated to meet the new criteria. "GBI", for example, would no longer be 3/0 (as in continent subset 3, index 0) and become 48.
I would extend this with a parentid that references the continent table, to allow the database to only present country options that match the selected continent. It could also allow a country to be selected and the appropriate continent to be populated automatically. A similar approach would be extended to my personal bugbear discussed earlier in the thread, the local region codes - these roughly equate to "states" for the US, "counties" for the UK, etc.
You might be wondering what continent/country/local codes could be used. I'd refer you to my previous post discussing the potential for reverse-geocoding to tackle this problem and bring the data into ISO compliance.
At this stage, I'd say we're close enough to 2NF to call it good. Shall we go for 3NF? No. I mean, we could, and there's an argument that it's almost 3NF as it stands (especially if decimal degrees are computed on the fly - which is entirely viable as we're pulled the DMS from the database in most cases and may not even use the decimal degrees) but I'm drawing the line at 2NF so I don't feel guilty about doing a bit of fiddling. Although I haven't checked the mathematics, I suspect that a "search within radius" function will probably work better with DD so I would like to have it stored in a column rather than calculate it 18,000+ times every time we run a search that is already going to be computation-heavy. This extra column would violate 3NF (remembering that we're ignoring the fact that we're already technically violating 1NF) as we're also storing the DMS as separate integers to ensure accuracy against the original record.
What about the second table? Text lives in that table quite happily. Reference is already a... well, reference, or more specifically a foreign key to another table. "Pinpoint" as I call it (or "page number" if you prefer) is a bit more difficult. It technically relies on the reference field to give it meaning, which isn't exactly 3NF compliant. My solution for this would be to create a single column in the table that holds a foreign key for the "pinpoint" table. The pinpoint table would hold the pinpoint and, as a pinpoint will only ever refer to one source, a foreign key for the "reference" table. This enables our casenote table to pull up the pinpoint, which can drag the appropriate reference in with it. It's also more compliant with 1-3NF, which I'm still pretending is the goal.
There is one possible elephant left in the room. Record ID. This makes the most logical primary key for the whole shebang. I was toying with the idea of having a system-unique id as an autoincrementing primary id and make a seperate record id. This rather goes against the spirit of avoiding duplication and there doesn't seem to be a compelling reason for doing so, so I'll continue with this as the primary key unless a good reason to reconsider arises. I should point out that the records don't actually have an id - the id is computed based on the pointer position within the file. If you jump 5 * 102bytes, you're at record #5. This is why I had initially considered creating a canonical reference and a system-specific reference.
Let's start making some tables using pseudo-sql... however it will be in the next post as I appear to have hit a character limit halfway through laying out the first table
Since the author gave permission, would it be possible to upload a disk image of the original floppy? I have an old Win 95 machine I'd like to try it
on.
Thanks
Thanks
And here's my initial proposed layout, using sql pseudo code for fun and frolics:
incident //Main table that will serve as the link for everything else
incident.id INT(10) UNSIGNED NOT NULL AUTOINCREMENT, //equates to record id
incident.year SMALLINT(5),
incident.month TINYINT(2),
incident.day TINYINT(2),
incident.hour TINYINT(2),
incident.minute TINYINT(2),
incident.duration SMALLINT(5),
incident.ymdtY TINYINT(1),
incident.ymdtM TINYINT(1),
incident.ymdtD TINYINT(1),
incident.ymdtT TINYINT(1),
incident.longitudeD SMALLINT(3),
incident.longitudeM SMALLINT(3),
incident.longitudeS SMALLINT(3),
incident.longitudeCardinal CHAR(1),
incident.longitudeDecimal DECIMAL(15,12), //contentious and not really *NF compliant!
incident.latitudeD SMALLINT(3),
incident.latitudeM SMALLINT(3),
incident.latitudeS SMALLINT(3),
incident.latitudeCardinal CHAR(1),
incident.latitudeDecimal DECIMAL(15,12), //contentious and not really *NF compliant!
incident.altitude INT,
incident.relativeelevation INT,
incident.terrain INT(10) UNSIGNED, //refers to another table
incident.localregion INT(10) UNSIGNED, //refers to another table - see note below
The foreign keys are, hopefully obviously, incident.terrain (terrain.id) and incident.localregion (localregion.id).
The indices are going to be... err... probably "index all the things!" applies here Realisitically, the DMS doesn't need to be indexed but the DD would be, especially if it's going to be used for "search by radius" functions. I struggle to see value in indexing the YMDT fields, though perhaps the researchers might find it very useful to filter by certainty as to the time and date? That just seems... well it wouldn't be my first thought.
On the plus side, however, the database will have low input requirements. The VAST majority of access is going to be read-only and, outside of the initial data import, it may never see a new record added. Thus, the issue of over-indexing is limited, meaning I don't feel so bad about indexing most of those fields.
There is an argument for the accuracy (YMTD) being moved into the more subjective casenote table as it is an assessment of the evidence rather than a "fact".
You might notice that the table only contains the local region. Each local region should only exist within one country, which should only exist within one continent. This isn't actually true, however, as it breaks the minute you try "somewhere in the middle of the Atlantic Ocean". I feel confident that there is a clean way to make the logic work, however, so I'll leave it like that for now.
Let's look at the second part of the record, the "case note".
casenote //table
casenote.id INT(10) UNSIGNED NOT NULL AUTOINCREMENT,
casenote.parentid INT(10) UNSIGNED, i]//link to incident table using record id
casenote.author INT(10) UNSIGNED, //refers to another table
casenote.text TEXT,
casenote.pinpoint INT(10) UNSIGNED, //refers to another table
casenote.strangeness INT(10) UNSIGNED, //refers to another table
casenote.credibility INT(10) UNSIGNED //refers to another table
The foreign keys are, hopefully obviously,casenote.parentid (incident.id), casenote.pinpoint (pinpoint.id), casenote.strangeness (strangeness.id), and casenote.credibility (credibility.id).
Indexing... as discussed above!
This table is currently just reflecting the existing LH data. I am going to ask for opinions on extending this out to capture a wider range of data, on the assumption that people may wish to add more records in the future. The author field allows the identification of records from the original dataset and filtering for those authored by a specific person, ie LH.
You may also notice that strangeness and credibility are not being stored in this table, but rather referring to another lookup table. This is more in the spirit of normalisation, plus on a practical level it allows a table that contains the code and even a description of what that level represents.
I am proposing to move the 64 attributes to a separate table (or, potentially, tables by category, thanks to the reuse of three letter codes in different categories in the original program) and connect them to the case note rather than the incident. This is because I consider the attributes to be an assessment of the evidence by the casenote author, rather than a record of the incident itself. I would welcome any thoughts on this, however. If you're excited by the idea of me typing out all 64 attributes for your enjoyment... I'm afraid I will have to disappoint you
I'll leave the imagination of the remaining tables and fields as an exercise for the reader. I am sure that I have forgotten or skipped something, but I wanted to have something set out to invite comments from those who are more knowledgeable in the voodoo that constitutes database design.
incident //Main table that will serve as the link for everything else
incident.id INT(10) UNSIGNED NOT NULL AUTOINCREMENT, //equates to record id
incident.year SMALLINT(5),
incident.month TINYINT(2),
incident.day TINYINT(2),
incident.hour TINYINT(2),
incident.minute TINYINT(2),
incident.duration SMALLINT(5),
incident.ymdtY TINYINT(1),
incident.ymdtM TINYINT(1),
incident.ymdtD TINYINT(1),
incident.ymdtT TINYINT(1),
incident.longitudeD SMALLINT(3),
incident.longitudeM SMALLINT(3),
incident.longitudeS SMALLINT(3),
incident.longitudeCardinal CHAR(1),
incident.longitudeDecimal DECIMAL(15,12), //contentious and not really *NF compliant!
incident.latitudeD SMALLINT(3),
incident.latitudeM SMALLINT(3),
incident.latitudeS SMALLINT(3),
incident.latitudeCardinal CHAR(1),
incident.latitudeDecimal DECIMAL(15,12), //contentious and not really *NF compliant!
incident.altitude INT,
incident.relativeelevation INT,
incident.terrain INT(10) UNSIGNED, //refers to another table
incident.localregion INT(10) UNSIGNED, //refers to another table - see note below
The foreign keys are, hopefully obviously, incident.terrain (terrain.id) and incident.localregion (localregion.id).
The indices are going to be... err... probably "index all the things!" applies here Realisitically, the DMS doesn't need to be indexed but the DD would be, especially if it's going to be used for "search by radius" functions. I struggle to see value in indexing the YMDT fields, though perhaps the researchers might find it very useful to filter by certainty as to the time and date? That just seems... well it wouldn't be my first thought.
On the plus side, however, the database will have low input requirements. The VAST majority of access is going to be read-only and, outside of the initial data import, it may never see a new record added. Thus, the issue of over-indexing is limited, meaning I don't feel so bad about indexing most of those fields.
There is an argument for the accuracy (YMTD) being moved into the more subjective casenote table as it is an assessment of the evidence rather than a "fact".
You might notice that the table only contains the local region. Each local region should only exist within one country, which should only exist within one continent. This isn't actually true, however, as it breaks the minute you try "somewhere in the middle of the Atlantic Ocean". I feel confident that there is a clean way to make the logic work, however, so I'll leave it like that for now.
Let's look at the second part of the record, the "case note".
casenote //table
casenote.id INT(10) UNSIGNED NOT NULL AUTOINCREMENT,
casenote.parentid INT(10) UNSIGNED, i]//link to incident table using record id
casenote.author INT(10) UNSIGNED, //refers to another table
casenote.text TEXT,
casenote.pinpoint INT(10) UNSIGNED, //refers to another table
casenote.strangeness INT(10) UNSIGNED, //refers to another table
casenote.credibility INT(10) UNSIGNED //refers to another table
The foreign keys are, hopefully obviously,casenote.parentid (incident.id), casenote.pinpoint (pinpoint.id), casenote.strangeness (strangeness.id), and casenote.credibility (credibility.id).
Indexing... as discussed above!
This table is currently just reflecting the existing LH data. I am going to ask for opinions on extending this out to capture a wider range of data, on the assumption that people may wish to add more records in the future. The author field allows the identification of records from the original dataset and filtering for those authored by a specific person, ie LH.
You may also notice that strangeness and credibility are not being stored in this table, but rather referring to another lookup table. This is more in the spirit of normalisation, plus on a practical level it allows a table that contains the code and even a description of what that level represents.
I am proposing to move the 64 attributes to a separate table (or, potentially, tables by category, thanks to the reuse of three letter codes in different categories in the original program) and connect them to the case note rather than the incident. This is because I consider the attributes to be an assessment of the evidence by the casenote author, rather than a record of the incident itself. I would welcome any thoughts on this, however. If you're excited by the idea of me typing out all 64 attributes for your enjoyment... I'm afraid I will have to disappoint you
I'll leave the imagination of the remaining tables and fields as an exercise for the reader. I am sure that I have forgotten or skipped something, but I wanted to have something set out to invite comments from those who are more knowledgeable in the voodoo that constitutes database design.
originally posted by: EvillerBob
I'd almost consider this to be the first normal form (1NF) for the database, as the incident and case note are, philosophically at least, two slightly different sets of data. I say "almost" as in my version I'm storing the location as both DMS and Decimal Degrees. For... reasons. However, I'll gloss over this with some handwaving about them conceptually representing "different bits of data" and pretend that the table is now 1NF compliant.
Normalisation is good, but how we need to use the data is more important.

From all you explanations I think you are doing a great job and I agree with your decisions.
originally posted by: ArMaP
From all you explanations I think you are doing a great job and I agree with your decisions.
Kind of you to say so. I'm throwing this out and inviting comment from experienced members because, when all is said and done, I'm a lawyer not a database engineer!
Hi there,
I would like to make the data available before building more software. To do so, I implemented a CSV export. It generates a CSV file that you can find here. As I said some bits are still unknown, but I would like to get some early feedback on how easy you can import it in your spreadsheet software (remember to specify that the separator is a Tab character, not a comma or a semicolon ; worked for me in Google Spreadsheet) and how easy you can use the data (typically you might consider some exported data format not useful).
So feel free to provide any feedback
Regarding a database structure, I would be inclined to keep the data structure as simple/fast as it was originally : a single table, with references to hardcoded (in the source code) values as long as they are constants (continents, countries, etc.). But I did not think about it much more than that, as I want to stay focused on fixing the latest decoding mysteries (pinpoint as pages, issues, volumes...) first, as I assume people want access to the data first, before any other software (but making such a software available online is definitely something to do for sure).
I would like to make the data available before building more software. To do so, I implemented a CSV export. It generates a CSV file that you can find here. As I said some bits are still unknown, but I would like to get some early feedback on how easy you can import it in your spreadsheet software (remember to specify that the separator is a Tab character, not a comma or a semicolon ; worked for me in Google Spreadsheet) and how easy you can use the data (typically you might consider some exported data format not useful).
So feel free to provide any feedback
Regarding a database structure, I would be inclined to keep the data structure as simple/fast as it was originally : a single table, with references to hardcoded (in the source code) values as long as they are constants (continents, countries, etc.). But I did not think about it much more than that, as I want to stay focused on fixing the latest decoding mysteries (pinpoint as pages, issues, volumes...) first, as I assume people want access to the data first, before any other software (but making such a software available online is definitely something to do for sure).
edit on
22/3/2017 by javarome because: (no reason given)
a reply to: ArMaP
Ok, I exported an Excel version from the CSV imported in Google Spreadsheet.
It contains more human-readable data, but this some flags have still to be expanded and some bits decoded.
Ok, I exported an Excel version from the CSV imported in Google Spreadsheet.
It contains more human-readable data, but this some flags have still to be expanded and some bits decoded.
originally posted by: javarome
Regarding a database structure, I would be inclined to keep the data structure as simple/fast as it was originally : a single table, with references to hardcoded (in the source code) values as long as they are constants (continents, countries, etc.). But I did not think about it much more than that, as I want to stay focused on fixing the latest decoding mysteries (pinpoint as pages, issues, volumes...) first, as I assume people want access to the data first, before any other software (but making such a software available online is definitely something to do for sure).
Except it isn't simple, and fast is a bit relative. For example, searching against a 64 bit mask (or 8 x 8bit masks). It's far slower and processor-intensive under SQL than it needs to be. It also goes against the principles of atomicity that underpin good db design, without any real benefit to justify that fairly extreme level of denormalising.
My goal is to also make it a data set that can grow. The database as it stands relies entirely on one author maintaining consistency with his own personal reference system that is, in places, a bit vague. If the data set will only ever be what it currently is, there is no issue. I would be happier not painting myself into that corner, however.
I'm also moving on to this stage for a reason that points back to the mystery bytes. It allows me to (more easily) run searches against the data to identify and present patterns that we can then investigate.
There is also value in dividing labour, and from following your progress you're doing some great work there
originally posted by: javarome
a reply to: ArMaP
Ok, I exported an Excel version from the CSV imported in Google Spreadsheet.
Excel warned me that it found unreadable content. "Repairing" the file gave me this:
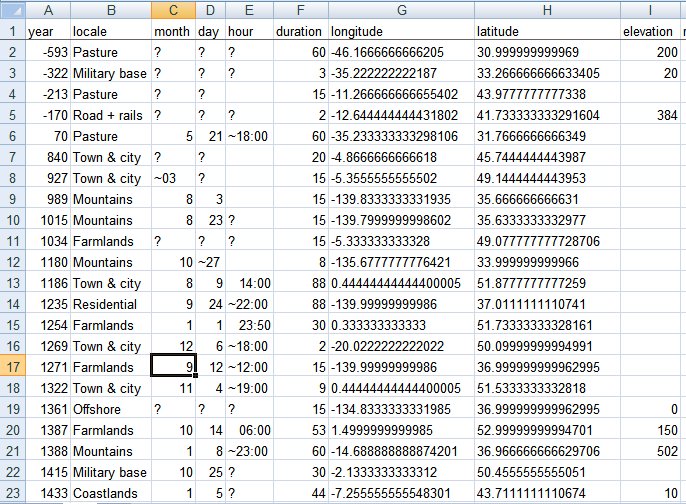
It looks like if you use ";" instead of tab as a separator Excel not only accepts it, it also opens it directly, with no need of importing it.
a reply to: ArMaP
Ok, I updated the export to use a standard comma (works better than semicolon) and expanded the flags:
- CSV export
- imported into Google Spreasheet
- exported as Excel file
Ok, I updated the export to use a standard comma (works better than semicolon) and expanded the flags:
- CSV export
- imported into Google Spreasheet
- exported as Excel file
Why Records #72 and #76 are interesting: a Tale By Bob of Eviller
It's nothing to do with the subject matter, actually. If you really are that keen to know, the records are about glowing orbs and disks in France, but that's not what makes them interesting.
The thing to look at is the reference and, more specifically, the issue number.
As complained about ad naseum, there is some mechanism for the program to identify when it needs to use a page number, or an issue number, or volume number, or one of a few other options. But that's not what caught my eye here.
Formatting on ATS sucks, but let's try to tabulate things a little. I'll use the IK Printout for identifying what the pinpoint should be, then look at the data I'm extracting to see what I'm actually getting, before comparing it to what I should be seeing for some sample records.
Record / Pinpoint / Actual Binary / Actual Decimal / Expected Binary
2 / "Issue No. 320" / 01000000 / 64 / 320 = 0b101000000
72 / "Issue No. 313" / 0b00111001 / 57 / 313 = 0b100111001
76 / "Issue No. 326" / 0b01000110 / 70 / 326 = 0b101000110
We've established that the pinpoint (or page reference if you prefer) field is one byte. That's 8 bits. Except... 8 bits can hold up to 255; you need 9 bits to hold 313 (0b100111001) or 326 (0b101000110). Looking at what we're reading and what we're expecting, you can see that what we are extracting is correct but incomplete. Somewhere, there are a few more bits that need to be attached to this byte.
Let's look a bit closer at Record #2. We have 0b01000000, but what we need is 0b101000000.
We already suspect that the "day" byte is split into two, with the day held from bits 3. If we check the mystery bits, we find 0b001. If this is the missing bit of our pinpoint, we can concat this to have 0b00101000000 = 320.
Aha! Let's check that against the other records.
Record #72: We have 0b00111001, we want 0b100111001. Our mystery bits are... 0b001. So now we have 0b00100111001 = 313
Record #76: We have 0b01000110, we want 0b10b01000110. Our mystery bits are... 0b001. So now we have 0b00101000110 = 326
On the basis of consistency across these three fields, I am provisionally declaring that the pinpoint reference is actually a combination of 3 bits from the date byte and the entirety of the pinpoint byte. This will still need further cross referencing against a random selection but it seems to be holding up on cursory examination at least.
None of which actually answers the question I was trying to answer (how the hell does it know when it needs to show volume/issue/page/etc?!?) but it's probably quite important in terms of data integrity and... stuff.
It's nothing to do with the subject matter, actually. If you really are that keen to know, the records are about glowing orbs and disks in France, but that's not what makes them interesting.
72: 1812/04/00 20:00 2 5:55:00 E 43:55:00 N 3212 WEU FRN AHP 8:6
NE/MANOSQUE,FR:7 OBS:LUMn.GLOBE >OVR ROAD:4 FIGs W/LITES INSIDE:volcano active
Ref#194 LUMIERES dans la NUIT.(LDLN France) Issue No. 313 : ROAD+RAILS
76: 1817/09/25 18:30 3 3:34:40 E 44:30:00 N 3333 WEU FRN LZR 6:8
LANEJOIS,FR:3 OBS:RED-GLO DISK DISK > nr ROMAN RUINS/2-3min:/JOURNAL de LOZERE
Ref#194 LUMIERES dans la NUIT.(LDLN France) Issue No. 326 : FARMLANDS
The thing to look at is the reference and, more specifically, the issue number.
As complained about ad naseum, there is some mechanism for the program to identify when it needs to use a page number, or an issue number, or volume number, or one of a few other options. But that's not what caught my eye here.
Formatting on ATS sucks, but let's try to tabulate things a little. I'll use the IK Printout for identifying what the pinpoint should be, then look at the data I'm extracting to see what I'm actually getting, before comparing it to what I should be seeing for some sample records.
Record / Pinpoint / Actual Binary / Actual Decimal / Expected Binary
2 / "Issue No. 320" / 01000000 / 64 / 320 = 0b101000000
72 / "Issue No. 313" / 0b00111001 / 57 / 313 = 0b100111001
76 / "Issue No. 326" / 0b01000110 / 70 / 326 = 0b101000110
We've established that the pinpoint (or page reference if you prefer) field is one byte. That's 8 bits. Except... 8 bits can hold up to 255; you need 9 bits to hold 313 (0b100111001) or 326 (0b101000110). Looking at what we're reading and what we're expecting, you can see that what we are extracting is correct but incomplete. Somewhere, there are a few more bits that need to be attached to this byte.
Let's look a bit closer at Record #2. We have 0b01000000, but what we need is 0b101000000.
We already suspect that the "day" byte is split into two, with the day held from bits 3. If we check the mystery bits, we find 0b001. If this is the missing bit of our pinpoint, we can concat this to have 0b00101000000 = 320.
Aha! Let's check that against the other records.
Record #72: We have 0b00111001, we want 0b100111001. Our mystery bits are... 0b001. So now we have 0b00100111001 = 313
Record #76: We have 0b01000110, we want 0b10b01000110. Our mystery bits are... 0b001. So now we have 0b00101000110 = 326
On the basis of consistency across these three fields, I am provisionally declaring that the pinpoint reference is actually a combination of 3 bits from the date byte and the entirety of the pinpoint byte. This will still need further cross referencing against a random selection but it seems to be holding up on cursory examination at least.
None of which actually answers the question I was trying to answer (how the hell does it know when it needs to show volume/issue/page/etc?!?) but it's probably quite important in terms of data integrity and... stuff.
edit on Ev14FridayFridayAmerica/ChicagoFri, 24 Mar 2017 18:14:44 -05000102017b by EvillerBob because: (no reason given)
And inconsistencies start to appear. Except... I'm not entirely sure that they are inconsistencies. If there is some other indicator of record type,
then it may be differences in how the data is interpreted. It remains consistent across the cases where I expect it to be consistent, with the
occasional problems where you find volume and issue (and possibly others, but this stood out)
Let's look briefly at Record #98:
The important part here is "Volume 28 Issue 10".
Our mystery bits are 0b001. Our pinpoint is 0b01011010 = 90. Combining them becomes 0b00101011010 = 346.
What we want to get, somehow, are the numbers "28" ( = 0b11100 ) and "10" ( = 0b1010 ).
There are two positions in the binary string that could represent 10 but no positions that could represent 28.
What about our other mystery bits, the ones found in the month byte? They remain annoyingly silent. I actually have an observation to make about those but want to make some inquiries first
It's all a bit of a puzzle.
There is something left, somewhere, that we are missing. As it stands, the data extracted up until this point is invalid because the pinpoints are incorrect Or, rather, it is mostly correct, but there is one particular field in the data set which is consistently wrong under certain conditions.
It was just unfortunate that I somehow managed to avoid checking on a record with a pinpoint greater than 255 until tonight.
Let's look briefly at Record #98:
98: 1863/08/12 23:00 60 3:40:00 W 40:27:00 N 3331 WEU SPN MDR 4:8
E/MADRID,SP:LUMn.OBJ/HRZN:HALO/TOP:HVRS then MNVRS/ALL DIRs:/Gaceta de Madrid
Ref#210 The APRO BULLETIN. (J & C Lorenzen) Volume 28 Issue 10 : METROPOLIS
The important part here is "Volume 28 Issue 10".
Our mystery bits are 0b001. Our pinpoint is 0b01011010 = 90. Combining them becomes 0b00101011010 = 346.
What we want to get, somehow, are the numbers "28" ( = 0b11100 ) and "10" ( = 0b1010 ).
There are two positions in the binary string that could represent 10 but no positions that could represent 28.
What about our other mystery bits, the ones found in the month byte? They remain annoyingly silent. I actually have an observation to make about those but want to make some inquiries first
It's all a bit of a puzzle.
There is something left, somewhere, that we are missing. As it stands, the data extracted up until this point is invalid because the pinpoints are incorrect Or, rather, it is mostly correct, but there is one particular field in the data set which is consistently wrong under certain conditions.
It was just unfortunate that I somehow managed to avoid checking on a record with a pinpoint greater than 255 until tonight.
As I'm running searches against the data anyway, I'm posting this both for my own reference later and for others with the data to consider (or even
confirm if you're feeling nice, it might be an error with my searching!):
Unknown 3 (byte between duration and longitude)
The following records contain something in Unknown 3:
Record / Binary / Decimal
#2602 / 00000001 / 1
#4472 / 00000100 / 4
#4519 / 00000011 / 3
#4846 / 00000101 / 5
#4925 / 00000001 / 1
#5002 / 00000001 / 1
#9058 / 00000001 / 1
Unknown 6 (byte between altitude and continent/country)
The following records contain something in Unknown 6:
None. Returns blank for all records.
Unknown 3 (byte between duration and longitude)
The following records contain something in Unknown 3:
Record / Binary / Decimal
#2602 / 00000001 / 1
#4472 / 00000100 / 4
#4519 / 00000011 / 3
#4846 / 00000101 / 5
#4925 / 00000001 / 1
#5002 / 00000001 / 1
#9058 / 00000001 / 1
Unknown 6 (byte between altitude and continent/country)
The following records contain something in Unknown 6:
None. Returns blank for all records.
a reply to: EvillerBob
Hi Bob,
Good analysis again, thanks for spotting that. I also identified that a high bit was missing to complete a high page number, but did not find which one to choose. Despite of the inconsistencies, I believe you spotted the good one, and that some another allows to interpret the whole bitset differently (i.e. as volume+issue) instead of page number. I've updated my code to use this new finding, as it can only be better than before, even if not perfect yet.
Regarding your database structure, you are right about bitmasks such as the ones encoding flags. Of course each of them need to be expanded as individual columns, so that we can apply SQL filter on them individually (i.e. search for cases with that flag only). This applies on CSV format as well, as people may want to search/filter spreadsheet rows on a similar criterion basis.
Now, speaking about normal forms, I agree that you should need more than one single table to avoid data redundancy for repeated references such as cases sources, or even continent/countries, states/province, etc. However I'm not sure about splitting between "factual" and "analysis". This is more a conceptual distinction than a database requirement, as both are strongly tied... unless you want to allow storing multiple analysis of the same case, and even some "factual" data can differ/be challenged in different analysis. But, once again, this is just my two cents.
Hi Bob,
Good analysis again, thanks for spotting that. I also identified that a high bit was missing to complete a high page number, but did not find which one to choose. Despite of the inconsistencies, I believe you spotted the good one, and that some another allows to interpret the whole bitset differently (i.e. as volume+issue) instead of page number. I've updated my code to use this new finding, as it can only be better than before, even if not perfect yet.
Regarding your database structure, you are right about bitmasks such as the ones encoding flags. Of course each of them need to be expanded as individual columns, so that we can apply SQL filter on them individually (i.e. search for cases with that flag only). This applies on CSV format as well, as people may want to search/filter spreadsheet rows on a similar criterion basis.
Now, speaking about normal forms, I agree that you should need more than one single table to avoid data redundancy for repeated references such as cases sources, or even continent/countries, states/province, etc. However I'm not sure about splitting between "factual" and "analysis". This is more a conceptual distinction than a database requirement, as both are strongly tied... unless you want to allow storing multiple analysis of the same case, and even some "factual" data can differ/be challenged in different analysis. But, once again, this is just my two cents.
a reply to: ArMaP
Hi ArMap,
Unfortunately, Google Spreadsheets fails to parse my CSV generated with a semicolon (maybe there is something incorrect in it, but didn't find out, whereas commas and tabs work fine), so I'm unable to generate an Excel file from such non-importable CSV (you got it: I don't have Excel). I'll investigate further in any case as support for Excel is critical, and other Excel users are welcome to test the files (maybe that a matter of Excel version for example):
- generated CSV file
- imported Google Spreadsheet
- Excel export
Hi ArMap,
Unfortunately, Google Spreadsheets fails to parse my CSV generated with a semicolon (maybe there is something incorrect in it, but didn't find out, whereas commas and tabs work fine), so I'm unable to generate an Excel file from such non-importable CSV (you got it: I don't have Excel). I'll investigate further in any case as support for Excel is critical, and other Excel users are welcome to test the files (maybe that a matter of Excel version for example):
- generated CSV file
- imported Google Spreadsheet
- Excel export
new topics
-
Planned Civil War In Britain May Be Triggered Soon
Social Issues and Civil Unrest: 37 minutes ago -
Claim: General Mark Milley Approved Heat and Sound Directed Energy Weapons During 2020 Riots
Whistle Blowers and Leaked Documents: 2 hours ago
top topics
-
Claim: General Mark Milley Approved Heat and Sound Directed Energy Weapons During 2020 Riots
Whistle Blowers and Leaked Documents: 2 hours ago, 3 flags -
Planned Civil War In Britain May Be Triggered Soon
Social Issues and Civil Unrest: 37 minutes ago, 1 flags
active topics
-
Gravitic Propulsion--What IF the US and China Really Have it?
General Conspiracies • 26 • : fringeofthefringe -
Ukraine halts transit of Russian gas to Europe after a prewar deal expired
Political Conspiracies • 146 • : xuenchen -
Claim: General Mark Milley Approved Heat and Sound Directed Energy Weapons During 2020 Riots
Whistle Blowers and Leaked Documents • 8 • : rickymouse -
Sorry to disappoint you but...
US Political Madness • 37 • : matafuchs -
The Truth about Migrant Crime in Britain.
Social Issues and Civil Unrest • 24 • : angelchemuel -
Trudeau Resigns! Breaking
Mainstream News • 69 • : KrustyKrab -
Planned Civil War In Britain May Be Triggered Soon
Social Issues and Civil Unrest • 0 • : TimBurr -
Stuck Farmer And His Queue Jumping Spawn
Rant • 10 • : Cvastar -
Joe Biden gives the USA's Highest Civilian Honor Award to Hillary Clinton and George Soros.
US Political Madness • 59 • : mysterioustranger -
Greatest thing you ever got, or bought?
General Chit Chat • 24 • : mysterioustranger