It looks like you're using an Ad Blocker.
Please white-list or disable AboveTopSecret.com in your ad-blocking tool.
Thank you.
Some features of ATS will be disabled while you continue to use an ad-blocker.

Discussing the gaps in evolution theory
page: 8share:
a reply to: Phantom423
Probably not, usually people will evolve artificial neural networks, and those networks typically aren't Turing complete. But if you look at his most recent paper from this year it's titled "The Evolution of Logic Circuits for the Purpose of Protein Contact Map Prediction". Evolving logic circuits is very similar to what I was talking about because it's a very low level approach. With only a NAND gate or a NOR gate it's possible to create any other logic gate, which makes that approach functionally complete, however it's not quite Turing complete. To make it fully Turing complete the system needs to have some type of random access memory. The number of ways you can solve a problem is very limited without the ability to store values in memory so they can be read and re-written by other parts of the algorithm. This relates to the idea that an algorithm is more than a mathematical equation, some problems require the use of memory and complex control flows in order to be solved.
However the problem with having Turing completeness is that the search space becomes truly massive because it contains every computable algorithm. The real question is, what type of building blocks are best suited for finding solutions in that search space. We could use logic gates but when you think about that might be an inefficient approach because we have to put together quite a few logic gates just to create a logic circuit which can add two integers together. We don't want the system to spend ages learning how to put together logic gates in the correct combination just so it can add two numbers together, just like we don't want to simulate particle physics to achieve the end result of the particle behavior. That is why I believe a good solution is to use components which perform different mathematical operations on some input(s) and provide an output(s). I've generalized this concept into what I call "function units", with 1 or more inputs and 1 or more outputs.
The function of a unit could be addition or some basic logic operation, I want to include all the operations I think are critical for building an algorithm and all the operations required to make it Turing complete, but I also don't want to allow too many options because that may make it harder for the system to locate solutions. These units essentially take their input from some location in memory and output to some other location in memory, or perhaps the same location if the input and output both point to the same location. A combination of units would be considered a "module" and modularity can be achieved by building things out of these modules, like proteins are built from a set of amino acids, and those amino acids are built from basic elements. There's some other details I've left out but the point is, the paths evolution can take has nearly unlimited flexibility, the system used by the creatures is Turing complete and allows them to solve the problem in a vast number of ways.
On a slightly related note, I noticed that Adami has a very interesting paper from 2012 titled The use of information theory in evolutionary biology. In it he goes through the process of mathematically calculating the information capacity and content in biological molecules, making it very clear Noinden was wrong.
I'm wondering whether the program Adami wrote, "Avida", could be considered a "Turning complete" program?
Probably not, usually people will evolve artificial neural networks, and those networks typically aren't Turing complete. But if you look at his most recent paper from this year it's titled "The Evolution of Logic Circuits for the Purpose of Protein Contact Map Prediction". Evolving logic circuits is very similar to what I was talking about because it's a very low level approach. With only a NAND gate or a NOR gate it's possible to create any other logic gate, which makes that approach functionally complete, however it's not quite Turing complete. To make it fully Turing complete the system needs to have some type of random access memory. The number of ways you can solve a problem is very limited without the ability to store values in memory so they can be read and re-written by other parts of the algorithm. This relates to the idea that an algorithm is more than a mathematical equation, some problems require the use of memory and complex control flows in order to be solved.
However the problem with having Turing completeness is that the search space becomes truly massive because it contains every computable algorithm. The real question is, what type of building blocks are best suited for finding solutions in that search space. We could use logic gates but when you think about that might be an inefficient approach because we have to put together quite a few logic gates just to create a logic circuit which can add two integers together. We don't want the system to spend ages learning how to put together logic gates in the correct combination just so it can add two numbers together, just like we don't want to simulate particle physics to achieve the end result of the particle behavior. That is why I believe a good solution is to use components which perform different mathematical operations on some input(s) and provide an output(s). I've generalized this concept into what I call "function units", with 1 or more inputs and 1 or more outputs.
The function of a unit could be addition or some basic logic operation, I want to include all the operations I think are critical for building an algorithm and all the operations required to make it Turing complete, but I also don't want to allow too many options because that may make it harder for the system to locate solutions. These units essentially take their input from some location in memory and output to some other location in memory, or perhaps the same location if the input and output both point to the same location. A combination of units would be considered a "module" and modularity can be achieved by building things out of these modules, like proteins are built from a set of amino acids, and those amino acids are built from basic elements. There's some other details I've left out but the point is, the paths evolution can take has nearly unlimited flexibility, the system used by the creatures is Turing complete and allows them to solve the problem in a vast number of ways.
On a slightly related note, I noticed that Adami has a very interesting paper from 2012 titled The use of information theory in evolutionary biology. In it he goes through the process of mathematically calculating the information capacity and content in biological molecules, making it very clear Noinden was wrong.
Information is a key concept in evolutionary biology. Information stored in a biological organism’s genome is used to generate the organism and to maintain and control it. Information is also that which evolves. When a population adapts to a local environment, information about this environment is fixed in a representative genome. However, when an environment changes, information can be lost. At the same time, information is processed by animal brains to survive in complex environments, and the capacity for information processing also evolves. Here, I review applications of information theory to the evolution of proteins and to the evolution of information processing in simulated agents that adapt to perform a complex task.
edit on 31/7/2016 by ChaoticOrder because: (no reason given)
a reply to: ChaoticOrder
No gaps, only ignorance from ignorant people.
If you really want answers to your questions, go to this site and do some research:
www.talkorigins.org...
No gaps, only ignorance from ignorant people.
If you really want answers to your questions, go to this site and do some research:
www.talkorigins.org...
originally posted by: ReprobateRaccoon
Please excuse this science dunce, but couldn't man made things like Fukushima, or cosmic related events like comet impacts, introduce sudden changes to evolution?
Fukushima (and more notably Chernobyl) can introduce a flurry of point mutations that survive into succeeding generations so long as they aren't fatal mutations or sterilize the critters.
Extinction Level Events (ELE) like impacts, ice age, pandemic diseases etc introduce genetic bottlenecks where small populations of survivors pass on their DNA and those collected mutations can become more pronounced.
a reply to: ChaoticOrder
It's going to take a lot more than information Theory to put intelligent design on equal footing with modern evolutionary synthesis
It's going to take a lot more than information Theory to put intelligent design on equal footing with modern evolutionary synthesis
edit
on 31-7-2016 by TzarChasm because: (no reason given)
This is my quandry on gradual evolution over time:
I'll break it down into spans of time that are more easily understood. The problem with discussing millions of years is that our psyches are not set up to grasp that amount of time.
The domesticated dog has been with humans between 27,000 and 40,000 years, derived from gray wolf and/or tamyr stock.
For the purposes of this mental exercise I will low-ball the estimation and say that it has taken mankind 27,000 years to develop the variety of dogs we see in the world today.
In that 27,000 years of intelligently-thought-out development it is still possible for any dog to breed with modern wolves. Bear in mind that also takes into account 27,000 years of separate wolf development in the wild. The general definition of species are that they cannot create fertile offspring with related organisms in the same branch of life. So far as I am aware, dogs are still considered a subspecies of wolf.
So we have a situation where two lines of the same base creature have been secluded for 27,000 years and undergoing distinct breeding pressures that are unllike the other branch. But these pressures have not created separate species.
So I'm going to call the 27,000 years a 'Canine Domestication Era' (CDE) for the next part below.
It is generally agreed that the last extinction level event occurred 65,000,000 years ago. At this time mammals are believed to have been opportunistic/omnivorous rodent- or mole-like creatures that had developed the dental structure needed to consume certain plants as well as animal tissue. They had not been able to develop much further due to predatory dinosaur and proto-avian species.
Then the rock hit. Iridium layer, 'impact winter' for 2-3 decades, plants dying off, larger animal species starved out, etc.
So now the mammals had the ability to start developing and filling niches left behind by the dinosaurs.
65,000,000 divided by 27,000 equals 2408 CDE's. Like I said, I want to break this down into spans of time we can relate to.
So that means that those dinosaur-era rodents had 2408 intervals of time (CDE) to evolve into the plethora of mammal diversity we see today. Whales. Elephants. Humans. Wolves. Giraffes. Lions. Seals. Camels. Etc.
Even the Marsupials, Echinoderms and Echindas in Australia that were successfully segregated from the rest of the planet's biosphere diverged into their own niches.
So if we have not been able to intelligently breed dogs into a separate species from wolves in 1 CDE then how did the diversity of mammal life come about in 2408 CDE's?. The number of differences between a basic rodent body plan and an Elephant, Human or Sperm Whale seem to exceed 2408 modifications.
It gets worse if we go back and say humans have been breeding dogs for 40,000 years. if that were the case, there have only been 1625 CDE's.
That's my quandry that makes me go "Hmmm...."
I'll break it down into spans of time that are more easily understood. The problem with discussing millions of years is that our psyches are not set up to grasp that amount of time.
The domesticated dog has been with humans between 27,000 and 40,000 years, derived from gray wolf and/or tamyr stock.
For the purposes of this mental exercise I will low-ball the estimation and say that it has taken mankind 27,000 years to develop the variety of dogs we see in the world today.
In that 27,000 years of intelligently-thought-out development it is still possible for any dog to breed with modern wolves. Bear in mind that also takes into account 27,000 years of separate wolf development in the wild. The general definition of species are that they cannot create fertile offspring with related organisms in the same branch of life. So far as I am aware, dogs are still considered a subspecies of wolf.
So we have a situation where two lines of the same base creature have been secluded for 27,000 years and undergoing distinct breeding pressures that are unllike the other branch. But these pressures have not created separate species.
So I'm going to call the 27,000 years a 'Canine Domestication Era' (CDE) for the next part below.
It is generally agreed that the last extinction level event occurred 65,000,000 years ago. At this time mammals are believed to have been opportunistic/omnivorous rodent- or mole-like creatures that had developed the dental structure needed to consume certain plants as well as animal tissue. They had not been able to develop much further due to predatory dinosaur and proto-avian species.
Then the rock hit. Iridium layer, 'impact winter' for 2-3 decades, plants dying off, larger animal species starved out, etc.
So now the mammals had the ability to start developing and filling niches left behind by the dinosaurs.
65,000,000 divided by 27,000 equals 2408 CDE's. Like I said, I want to break this down into spans of time we can relate to.
So that means that those dinosaur-era rodents had 2408 intervals of time (CDE) to evolve into the plethora of mammal diversity we see today. Whales. Elephants. Humans. Wolves. Giraffes. Lions. Seals. Camels. Etc.
Even the Marsupials, Echinoderms and Echindas in Australia that were successfully segregated from the rest of the planet's biosphere diverged into their own niches.
So if we have not been able to intelligently breed dogs into a separate species from wolves in 1 CDE then how did the diversity of mammal life come about in 2408 CDE's?. The number of differences between a basic rodent body plan and an Elephant, Human or Sperm Whale seem to exceed 2408 modifications.
It gets worse if we go back and say humans have been breeding dogs for 40,000 years. if that were the case, there have only been 1625 CDE's.
That's my quandry that makes me go "Hmmm...."
a reply to: ChaoticOrder
Adami's Markov Network Brains found here: adamilab.msu.edu...
might be an interesting way of sorting information contained in the gene because:
1. the set of hidden nodes act as memory to store information
2. unlike classic logic gates which are deterministic, the MNB uses a probabilistic logic gates containing arbitrary information.
From his illustrations:



Once the gene numbers are filled in, they're converted into probabilities.
I was thinking that once you have the probabilities, perhaps the Viterbi algorithm could be used to find the likely sequence of hidden nodes? The hidden nodes act as memory - could you rinse and repeat to find the most statistically significant functional sequence? It looks like you would need a sorting capability to determine amongst the zillion permutations possible which ones are an absolute requirement to eventually include in the final algorithm.
All his programs are open source - I'm not a programmer, but perhaps you could download some of his software to see if it's useful for your project.
I'm still reading his papers - have to look up notation and definitions along the way so it takes time.
And yes, Noinden has been proven wrong. If he/she is a scientist the new information should be welcomed as adding to the knowledge base. If not a scientist and just arrogant, well you know the drill......
Adami's Markov Network Brains found here: adamilab.msu.edu...
might be an interesting way of sorting information contained in the gene because:
1. the set of hidden nodes act as memory to store information
2. unlike classic logic gates which are deterministic, the MNB uses a probabilistic logic gates containing arbitrary information.
From his illustrations:
Once the gene numbers are filled in, they're converted into probabilities.
I was thinking that once you have the probabilities, perhaps the Viterbi algorithm could be used to find the likely sequence of hidden nodes? The hidden nodes act as memory - could you rinse and repeat to find the most statistically significant functional sequence? It looks like you would need a sorting capability to determine amongst the zillion permutations possible which ones are an absolute requirement to eventually include in the final algorithm.
All his programs are open source - I'm not a programmer, but perhaps you could download some of his software to see if it's useful for your project.
I'm still reading his papers - have to look up notation and definitions along the way so it takes time.
And yes, Noinden has been proven wrong. If he/she is a scientist the new information should be welcomed as adding to the knowledge base. If not a scientist and just arrogant, well you know the drill......
a reply to: Teikiatsu
I understand your logic. But I don't think there's anything in evolution that says that the process has to be linear and the same for all organisms. If I understand you correctly, you're questioning why canines have not evolved into another species. Well it's a good question - but in order to really understand that, we would have to have mathematical models developed from canine research which could go back very far in time and then PROJECT or PREDICT when evolution to a new species would take place. We don't have that information, but I wouldn't be at all surprised if computerized technology will give us an answer. All we can say is that the canine genome must be stable to the extent that it always (at least up to now) produces a dog. I remember reading an article about the huge number of types the canine species has - it can be hybridized very easily. But it's still a dog.
An example of rapid evolution is given in this article - you can see from the illustration below that Paramo organisms have a much higher rate of newly evolved species that other parts of the world.
Páramo is the world's fastest evolving and coolest biodiversity hotspot
Santiago Madriñán1*, Andrés J. Cortés1,2 and James E. Richardson1,3
Understanding the processes that cause speciation is a key aim of evolutionary biology. Lineages or biomes that exhibit recent and rapid diversification are ideal model systems for determining these processes. Species rich biomes reported to be of relatively recent origin, i.e., since the beginning of the Miocene, include Mediterranean ecosystems such as the California Floristic Province, oceanic islands such as the Hawaiian archipelago and the Neotropical high elevation ecosystem of the Páramos. Páramos constitute grasslands above the forest tree-line (at elevations of c. 2800–4700 m) with high species endemism. Organisms that occupy this ecosystem are a likely product of unique adaptations to an extreme environment that evolved during the last three to five million years when the Andes reached an altitude that was capable of sustaining this type of vegetation. We compared net diversification rates of lineages in fast evolving biomes using 73 dated molecular phylogenies. Based on our sample, we demonstrate that average net diversification rates of Páramo plant lineages are faster than those of other reportedly fast evolving hotspots and that the faster evolving lineages are more likely to be found in Páramos than the other hotspots. Páramos therefore represent the ideal model system for studying diversification processes. Most of the speciation events that we observed in the Páramos (144 out of 177) occurred during the Pleistocene possibly due to the effects of species range contraction and expansion that may have resulted from the well-documented climatic changes during that period. Understanding these effects will assist with efforts to determine how future climatic changes will impact plant populations.
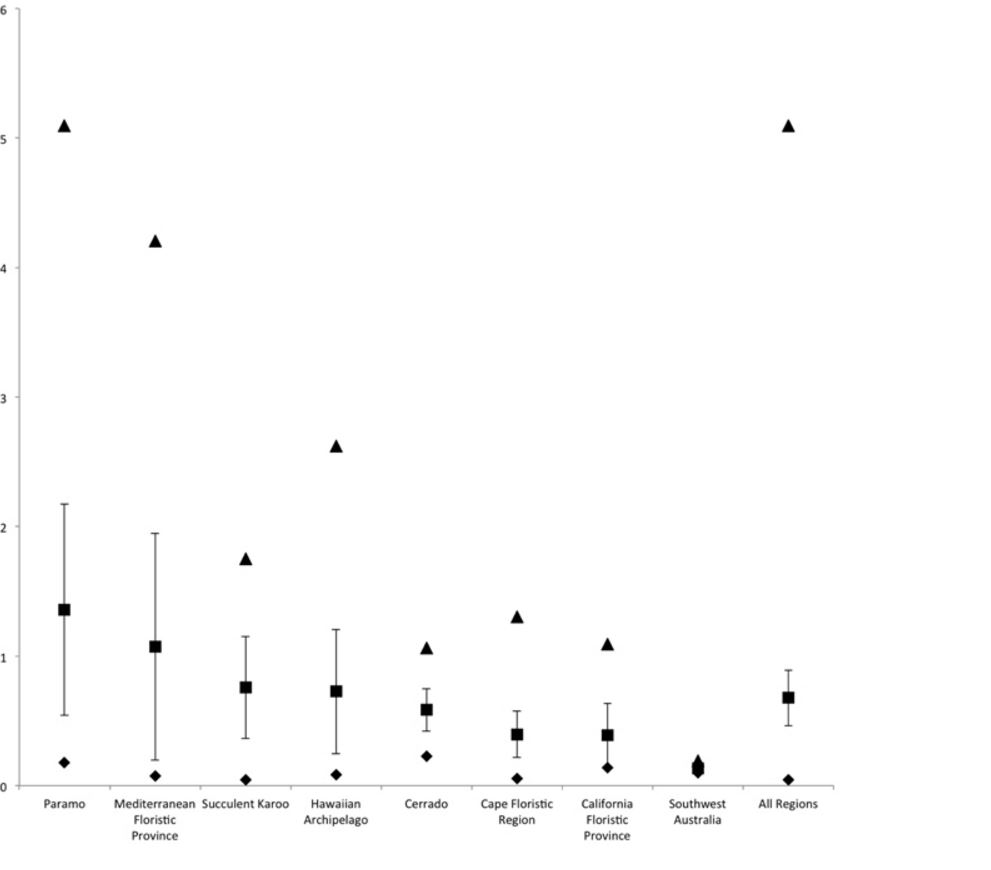
journal.frontiersin.org...
People ask why there are no "transitional fossils" around - well hell, they're all over the place - to include humans. The majority of life forms on this planet evolve over time - read about it here: www.transitionalfossils.com...
I understand your logic. But I don't think there's anything in evolution that says that the process has to be linear and the same for all organisms. If I understand you correctly, you're questioning why canines have not evolved into another species. Well it's a good question - but in order to really understand that, we would have to have mathematical models developed from canine research which could go back very far in time and then PROJECT or PREDICT when evolution to a new species would take place. We don't have that information, but I wouldn't be at all surprised if computerized technology will give us an answer. All we can say is that the canine genome must be stable to the extent that it always (at least up to now) produces a dog. I remember reading an article about the huge number of types the canine species has - it can be hybridized very easily. But it's still a dog.
An example of rapid evolution is given in this article - you can see from the illustration below that Paramo organisms have a much higher rate of newly evolved species that other parts of the world.
Páramo is the world's fastest evolving and coolest biodiversity hotspot
Santiago Madriñán1*, Andrés J. Cortés1,2 and James E. Richardson1,3
Understanding the processes that cause speciation is a key aim of evolutionary biology. Lineages or biomes that exhibit recent and rapid diversification are ideal model systems for determining these processes. Species rich biomes reported to be of relatively recent origin, i.e., since the beginning of the Miocene, include Mediterranean ecosystems such as the California Floristic Province, oceanic islands such as the Hawaiian archipelago and the Neotropical high elevation ecosystem of the Páramos. Páramos constitute grasslands above the forest tree-line (at elevations of c. 2800–4700 m) with high species endemism. Organisms that occupy this ecosystem are a likely product of unique adaptations to an extreme environment that evolved during the last three to five million years when the Andes reached an altitude that was capable of sustaining this type of vegetation. We compared net diversification rates of lineages in fast evolving biomes using 73 dated molecular phylogenies. Based on our sample, we demonstrate that average net diversification rates of Páramo plant lineages are faster than those of other reportedly fast evolving hotspots and that the faster evolving lineages are more likely to be found in Páramos than the other hotspots. Páramos therefore represent the ideal model system for studying diversification processes. Most of the speciation events that we observed in the Páramos (144 out of 177) occurred during the Pleistocene possibly due to the effects of species range contraction and expansion that may have resulted from the well-documented climatic changes during that period. Understanding these effects will assist with efforts to determine how future climatic changes will impact plant populations.
journal.frontiersin.org...
People ask why there are no "transitional fossils" around - well hell, they're all over the place - to include humans. The majority of life forms on this planet evolve over time - read about it here: www.transitionalfossils.com...
edit on 31-7-2016 by Phantom423 because: (no reason given)
edit on 31-7-2016 by Phantom423 because: (no reason
given)
edit on 31-7-2016 by Phantom423 because: (no reason given)
originally posted by: Phantom423
a reply to: ChaoticOrder
Adami's Markov Network Brains found here: adamilab.msu.edu...
might be an interesting way of sorting information contained in the gene because:
1. the set of hidden nodes act as memory to store information
2. unlike classic logic gates which are deterministic, the MNB uses a probabilistic logic gates containing arbitrary information.
The Hidden Markov model may be Turing complete because it has recurrent connections in the network which give it a sort of memory storage mechanism. However I think it's actually a bit more complicated than just having a memory storage mechanism. Artificial neural networks typically take the same amount of time to produce an answer every time because the calculations performed by each node are finite. However an arbitrary algorithm running on a Turing machine could take any amount of time to execute, and the Halting problem tells us there is no universal algorithm to determine how long any other algorithm will take to execute or if it will ever stop.
Humans generally take an indeterminate amount of time to solve a problem. If we think about the problem harder we can solve it more quickly and we burn more energy doing it. Our brains work a bit like a computer which can dynamically increase its clock speed to run faster when necessary. The frequency of our brain waves will shift and become more erratic when thinking intensely. It's worth asking the question, should we attempt to evolve creatures which perform an unpredictable number of computations to produce an answer. The human brain does perform a finite number of computations at every discrete moment in time but the number of steps required is unpredictable.
We're getting a bit beyond the realm of this discussion now though so let me get back on track. When it comes to neural networks and other similar networks the thing we need to keep in mind is that they are best suited for solving certain types of problems, usually anything which requires feature detection in a high dimensional data set. Even though it would be possible, no programmer would want to solve problems using only nodes in a network because it would be a very inefficient and difficult way of creating algorithms. Instead they will just use a powerful Turing complete programming language which allows them to solve it in a few lines of code and runs much faster.
The main reason artificial neural networks are so popular in the field of machine learning is because they're inspired by real neural networks and they can be trained using well known algorithms. But what we're talking about here is when the training algorithm is a genetic algorithm, something which doesn't search for the answer in a very specific mathematical way. So why restrict ourselves to these networking ideas when we can evolve pretty much any system we want. I would argue that using a recurrent network isn't the most efficient way to solve many problems if memory is required. When evolving virtual creatures we really need to consider the type of landscape they are evolving in.
They aren't evolving in a world with particle physics, they are evolving within the architecture of our computers, a world where everything is about CPU instructions reading and writing digital information to RAM. Think about the first theoretical idea of a Universal Turing Machine, it's essentially the same thing, just with infinite tape/memory and a little reading head which moves along the tape reading and writing to it based on some rules. Our computers are the real world example of that theoretical machine without the infinite memory capacity but they work on that same basic concept. I have thought about ways to evolve Turing-like machines by evolving some sort of instruction set.
I believe that has actually been done before, I remember reading something about it not too long ago. However I think the same problem would arise with that approach, again it would be difficult and time consuming for a programmer to solve a problem if they were just working with machine instructions. What we really want to aim for is something which allows the process of evolution to easily stumble upon solutions. By now you may have already thought "why not just evolve algorithms using actual programming languages if that's an easy and efficient way to solve problems?". Well the main reason is, a random combination of characters will rarely form valid code.
The vast majority of character combinations will contain syntax errors or some other error, so it would be difficult to evolve solutions using the random nature of evolution since barely anything would work. This is another reason we tend to use things like artificial neural networks in these systems, because regardless of how you put together the nodes, they will usually output some sort of answer, even if the answer is completely wrong. So a key idea here is to use components which don't totally blow up when we put them together in the wrong way. The function unit system I have described has that property and since the building blocks have useful functions it should be easy to produce solutions.
I want it to be easy to solve problems using these building blocks if all I had to create an algorithm were those building blocks, because then it should be easier for the process of evolution to stumble upon solutions. I have even considered methods of allowing the process of evolution to actually determine what the functions are, so the very building blocks the virtual agents are made out of would be subject to change. This is sort of like allowing the system to decide its own search space which is pretty mind bending stuff, but I believe I have read something on this topic at least once before, I just cannot remember what it was.
On the topic of probabilistic logic gates, a little bit of randomness is often a good thing because it encourages the use of general solutions which can work under unexpected conditions. The human brain is prone to random events like particle decay and unexpected problems can occur like neuron damage. Almost any machine learning model can benefit by injecting a little bit of entropy and unpredictability into the system. The way I plan to do it in my simulation is to add a little bit of noise to the outputs, maybe also simulate failing and dead components. Another idea is to give the function units direct access to an entropy pool (memory array full of random numbers).
edit on 31/7/2016 by ChaoticOrder because: (no reason
given)
a reply to: ChaoticOrder
I have to take one step at a time here as you're a professional in computer science and I'm not.
Regarding the excerpt from your post, how do we know that it isn't mathematical? Everything comes down to numbers. That might be a trite statement, but doesn't it? In chemistry, particularly in drug discovery, we think of functional groups - where are they, what do they do. NMR, mass spec, UV/IR gives us what? - a bunch of numbers about the compound and about the functional groups. We isolate, characterize and tear apart what we have until we find/or not find what we're looking for. For instance, we know that beta carotene is the precursor to Vitamin A. Now that we know the precursor, can I write an algorithm that will drive the components in a mixture to produce Vitamin A? Of course we can. What's so different about a genome? I'm probably thinking like a bench chemist, which is what I am, but if we didn't have the instrumentation mentioned above and had to rely on a computer model to figure out that beta carotene was the precursor to Vitamin A, I wonder if it would be possible and if possible, how long would it take?
I have a hard time visualizing that virtual world - if I was presented with the same problem I would start tearing things apart first to understand functionalities. Stanford came up with the Eterna program which seeks to modify RNA for drug/medicine discovery. Anyone can participate. The program is written as a game.
www.eternagame.org...
Here's the concept of the algorithm upon which the game is based:
Algorithms
Eterna Bot is a secondary structure algorithm designed to represent the distilled knowledge of RNA design patterns derived by human players of the game.
So what is this project really doing? It's essentially putting the lab online to discover what - if any - modifications can be made to RNA to produce some beneficial drug or medical application.
The point is if you don't know how the "thing" works, how can you write an algorithm to solve "its" problems?
Getting back to the code, we can do all the above - modify RNA, make drugs, do all sorts of fun things in the lab. But do we understand the underlying language of the RNA molecule? No. Again, if I were presented with this problem I would tear apart the molecule, study every functionality that was known and try to reverse engineer those functionalities to get to the "source code". In the end, if I discovered the source code, I should be able to take that molecule and control its production. Then, you could write the algorithm that governs all the functionalities of the RNA molecule.
But what we're talking about here is when the training algorithm is a genetic algorithm, something which doesn't search for the answer in a very specific mathematical way.
I have to take one step at a time here as you're a professional in computer science and I'm not.
Regarding the excerpt from your post, how do we know that it isn't mathematical? Everything comes down to numbers. That might be a trite statement, but doesn't it? In chemistry, particularly in drug discovery, we think of functional groups - where are they, what do they do. NMR, mass spec, UV/IR gives us what? - a bunch of numbers about the compound and about the functional groups. We isolate, characterize and tear apart what we have until we find/or not find what we're looking for. For instance, we know that beta carotene is the precursor to Vitamin A. Now that we know the precursor, can I write an algorithm that will drive the components in a mixture to produce Vitamin A? Of course we can. What's so different about a genome? I'm probably thinking like a bench chemist, which is what I am, but if we didn't have the instrumentation mentioned above and had to rely on a computer model to figure out that beta carotene was the precursor to Vitamin A, I wonder if it would be possible and if possible, how long would it take?
I have a hard time visualizing that virtual world - if I was presented with the same problem I would start tearing things apart first to understand functionalities. Stanford came up with the Eterna program which seeks to modify RNA for drug/medicine discovery. Anyone can participate. The program is written as a game.
www.eternagame.org...
Here's the concept of the algorithm upon which the game is based:
Algorithms
Eterna Bot is a secondary structure algorithm designed to represent the distilled knowledge of RNA design patterns derived by human players of the game.
So what is this project really doing? It's essentially putting the lab online to discover what - if any - modifications can be made to RNA to produce some beneficial drug or medical application.
The point is if you don't know how the "thing" works, how can you write an algorithm to solve "its" problems?
Getting back to the code, we can do all the above - modify RNA, make drugs, do all sorts of fun things in the lab. But do we understand the underlying language of the RNA molecule? No. Again, if I were presented with this problem I would tear apart the molecule, study every functionality that was known and try to reverse engineer those functionalities to get to the "source code". In the end, if I discovered the source code, I should be able to take that molecule and control its production. Then, you could write the algorithm that governs all the functionalities of the RNA molecule.
edit on 1-8-2016 by Phantom423 because: (no reason given)
I have to take one step at a time here as you're a professional in computer science and I'm not.
Regarding the excerpt from your post, how do we know that it isn't mathematical? Everything comes down to numbers. That might be a trite statement, but doesn't it?
I'm not a professional but I have done quite a bit of research and thinking on this topic. What I mean when I say the process of evolution does not discover solutions in a purely mathematical way is that the process relies heavily on random chance. With a neural network you could use an algorithm such as back propagation to train the network, which will adjust the network weights according to specific equations in order to reduce the error rate. But that algorithm will generally only work on very specific types of artificial neural networks.
Genetic algorithms are a general training method which can be applied to essentially any type of model if we can represent those models using some type of DNA structure and create a way to mix DNA of parents to generate new offspring. The process has a lot of random elements built into it, such as random mutations, the choice of which DNA to mix together to produce offspring, the setup of the very first generation and the differences between each creature, etc. That is why each time you run the simulation you will get very different results.
The problem I'm interested in is finding which types of building blocks work well with the process of evolution and the problem of how to evolve reproductive systems instead of hard coding those systems into the simulation. Clearly evolution doesn't just rely on the luck of the draw to produce solutions, it makes use of the random elements in a very efficient manner, which should be reflected in our simulations if we expect to see result better than what chance will give us. At the core of it is the reproduction mechanism, which is why I think it's critical to evolve the reproduction system rather than design it.
a reply to: ChaoticOrder
its dangerously arrogant to think that we have the right to modify evolution. although im not sure its really a concern, anymore than controlling the weather or making the earth stand still. we dont have that kind of technological prowess. good thing too.
The problem I'm interested in is finding which types of building blocks work well with the process of evolution and the problem of how to evolve reproductive systems instead of hard coding those systems into the simulation. Clearly evolution doesn't just rely on the luck of the draw to produce solutions, it makes use of the random elements in a very efficient manner, which should be reflected in our simulations if we expect to see result better than what chance will give us. At the core of it is the reproduction mechanism, which is why I think it's critical to evolve the reproduction system rather than design it.
its dangerously arrogant to think that we have the right to modify evolution. although im not sure its really a concern, anymore than controlling the weather or making the earth stand still. we dont have that kind of technological prowess. good thing too.
edit on 4-8-2016 by TzarChasm
because: (no reason given)
a reply to: ChaoticOrder
I think this has to start out as a stochastic optimization and programming problem - testing random variables to find the best fit. The "building blocks" could be generated through multiple runs of the stochastic program, eventually ruling out the most unlikely candidate and conversely, selecting the most likely candidate to be included in that particular "block". The result would be partially stochastic and partially deterministic.
The reproduction part of the program could be an iteration loop which runs until all the criteria is met for that particular block.
This type of work was done by John Holland - complicated stuff - above my pay grade! But interesting nonetheless.
J. Holland, Adaptation in Natural and Artificial Systems, The MIT Press; Reprint edition 1992 (originally published in 1975).
J. Holland, Hidden Order: How Adaptation Builds Complexity, Helix Books; 1996.
The problem I'm interested in is finding which types of building blocks work well with the process of evolution and the problem of how to evolve reproductive systems instead of hard coding those systems into the simulation.
I think this has to start out as a stochastic optimization and programming problem - testing random variables to find the best fit. The "building blocks" could be generated through multiple runs of the stochastic program, eventually ruling out the most unlikely candidate and conversely, selecting the most likely candidate to be included in that particular "block". The result would be partially stochastic and partially deterministic.
The reproduction part of the program could be an iteration loop which runs until all the criteria is met for that particular block.
This type of work was done by John Holland - complicated stuff - above my pay grade! But interesting nonetheless.
J. Holland, Adaptation in Natural and Artificial Systems, The MIT Press; Reprint edition 1992 (originally published in 1975).
J. Holland, Hidden Order: How Adaptation Builds Complexity, Helix Books; 1996.
edit on 5-8-2016 by Phantom423 because: (no reason
given)
edit on 5-8-2016 by Phantom423 because: (no reason given)
a reply to: ChaoticOrder
I may not be at a high enough level to help but let's do some brainstorming just for fun.
Do evolutionary changes actually happen as rapidly as the fossil records indicate? It's possible that small numbers of species existed before recorded fossils were left, and what we see could be interpreted either as and explosion of new species, or an outbreak of formerly endangered species. Your attempts to meet the rate of adaptation interpreted from the fossils may be futile if this was the case.
Why don't we see transitional species? A species with a mouth but missing a stomach or vice versa would go extinct quite rapidly. As far as I know everything is transitioning though; although some species such as sharks and alligators seem to be doing it more slowly. We have some species and subspecies on the fringe of speciation. Horses and Donkeys are close enough to have Mules, but not close enough for them to be fertile. On the other side of speciation, some breeds of dogs are almost incapable of intermixing, though they can still be readily mixed with a common breed. Would these count as intermediate species? Cases such as these may warrant more attention.
What could cause bursts of (relatively) rapid evolution? Obviously, rapid changes in environment. How about polarization? If for instance tall subspecies usually mixed with other tall subspecies, while short subspecies usually mixed with short subspecies, your units would slide towards the ends of the bell curve allowing you to cover a larger search space than unpolarized breeding (polarization has been observed in nature). If one or the other pole were to approach extinction it may drive the survivors to move to the other pole, giving a chance to introduce hybrid vigor.
If we were to represent stats such as height, weight, stamina, etc... on a multidimensional chart, you would find some interesting regions in this space. How much can you enlarge a design before it requires modification? Would a Flee the size of an Elephant be able to jump higher, or would it just break its legs in the effort? As species approached these spaces, you'd see some interesting adaptations come up that weren't encouraged (even discouraged) in the journey across the stable regions.
That's all I can think of for now.
I may not be at a high enough level to help but let's do some brainstorming just for fun.
Do evolutionary changes actually happen as rapidly as the fossil records indicate? It's possible that small numbers of species existed before recorded fossils were left, and what we see could be interpreted either as and explosion of new species, or an outbreak of formerly endangered species. Your attempts to meet the rate of adaptation interpreted from the fossils may be futile if this was the case.
Why don't we see transitional species? A species with a mouth but missing a stomach or vice versa would go extinct quite rapidly. As far as I know everything is transitioning though; although some species such as sharks and alligators seem to be doing it more slowly. We have some species and subspecies on the fringe of speciation. Horses and Donkeys are close enough to have Mules, but not close enough for them to be fertile. On the other side of speciation, some breeds of dogs are almost incapable of intermixing, though they can still be readily mixed with a common breed. Would these count as intermediate species? Cases such as these may warrant more attention.
What could cause bursts of (relatively) rapid evolution? Obviously, rapid changes in environment. How about polarization? If for instance tall subspecies usually mixed with other tall subspecies, while short subspecies usually mixed with short subspecies, your units would slide towards the ends of the bell curve allowing you to cover a larger search space than unpolarized breeding (polarization has been observed in nature). If one or the other pole were to approach extinction it may drive the survivors to move to the other pole, giving a chance to introduce hybrid vigor.
If we were to represent stats such as height, weight, stamina, etc... on a multidimensional chart, you would find some interesting regions in this space. How much can you enlarge a design before it requires modification? Would a Flee the size of an Elephant be able to jump higher, or would it just break its legs in the effort? As species approached these spaces, you'd see some interesting adaptations come up that weren't encouraged (even discouraged) in the journey across the stable regions.
That's all I can think of for now.
a reply to: Phantom423
Well holy #! How did we miss the elephant in the room?
The intelligence of Turkeys was once mentioned in a group of hunters. I was under the impression that they had an abysmal level of intelligence. I was reminded that Ben Franklin wanted the Turkey as the national bird due to its craftiness. I said: that's funny my mother told me they were so retarded they'd drown staring up at the rain. Someone else said 'yeah I have heard of that'. We were both confused. Then someone pointed out 'Now if you're talking about domestic Turkeys...'
So what hasn't been brought up in this discussion on propagation? Sex! Obviously the domestic turkeys aren't bread for IQ. Who does the breeding in the wild? Just natural selection? Why has nature made male female reproduction so popular? The livestock weren't satisfied with their breeder and they began to take matters into their own hands. A game was started with one side as 'it' tasked with spreading genes. Some species have some differences between male and female (for instance, one is larger than the other). Often the males just compete to spread their seed, while the female is in charge of rearing the young. Birds are fairly similar in their working roles, but are still divided in mail and female. Why do they retain such distinctive differences when their practical roles are so similar? Maybe if they abandoned the game, they would be less successful as breeders.
Perhaps Chaotic should add some 'free-range' units in their software and see what comes of it.
By the way, I sent you a U2U.
Well holy #! How did we miss the elephant in the room?
The intelligence of Turkeys was once mentioned in a group of hunters. I was under the impression that they had an abysmal level of intelligence. I was reminded that Ben Franklin wanted the Turkey as the national bird due to its craftiness. I said: that's funny my mother told me they were so retarded they'd drown staring up at the rain. Someone else said 'yeah I have heard of that'. We were both confused. Then someone pointed out 'Now if you're talking about domestic Turkeys...'
So what hasn't been brought up in this discussion on propagation? Sex! Obviously the domestic turkeys aren't bread for IQ. Who does the breeding in the wild? Just natural selection? Why has nature made male female reproduction so popular? The livestock weren't satisfied with their breeder and they began to take matters into their own hands. A game was started with one side as 'it' tasked with spreading genes. Some species have some differences between male and female (for instance, one is larger than the other). Often the males just compete to spread their seed, while the female is in charge of rearing the young. Birds are fairly similar in their working roles, but are still divided in mail and female. Why do they retain such distinctive differences when their practical roles are so similar? Maybe if they abandoned the game, they would be less successful as breeders.
Perhaps Chaotic should add some 'free-range' units in their software and see what comes of it.
By the way, I sent you a U2U.
new topics
-
Nov 2024 - Former President Barack Hussein Obama Has Lost His Aura.
US Political Madness: 1 hours ago -
Something better
Dissecting Disinformation: 6 hours ago -
The Witcher IV — Cinematic Reveal Trailer | The Game Awards 2024
Video Games: 9 hours ago -
Friday thoughts
General Chit Chat: 9 hours ago -
More Ons?
Political Conspiracies: 9 hours ago -
Canada Post strike ended by the Government of Canada
Mainstream News: 9 hours ago
top topics
-
They Know
Aliens and UFOs: 14 hours ago, 18 flags -
Something better
Dissecting Disinformation: 6 hours ago, 8 flags -
More Ons?
Political Conspiracies: 9 hours ago, 6 flags -
Friday thoughts
General Chit Chat: 9 hours ago, 5 flags -
Canada Post strike ended by the Government of Canada
Mainstream News: 9 hours ago, 4 flags -
Nov 2024 - Former President Barack Hussein Obama Has Lost His Aura.
US Political Madness: 1 hours ago, 3 flags -
The Witcher IV — Cinematic Reveal Trailer | The Game Awards 2024
Video Games: 9 hours ago, 2 flags -
Drones (QUESTION) TERMINATOR (QUESTION)
General Chit Chat: 15 hours ago, 1 flags
active topics
-
Drones everywhere in New Jersey
Aliens and UFOs • 108 • : Coelacanth55 -
Nov 2024 - Former President Barack Hussein Obama Has Lost His Aura.
US Political Madness • 5 • : Astrocometus -
They Know
Aliens and UFOs • 62 • : CarlLaFong -
More Ons?
Political Conspiracies • 18 • : rickymouse -
Something better
Dissecting Disinformation • 13 • : Astrocometus -
-@TH3WH17ERABB17- -Q- ---TIME TO SHOW THE WORLD--- -Part- --44--
Dissecting Disinformation • 3669 • : xuenchen -
A Bunch of Maybe Drones Just Flew Across Hillsborough County
Aircraft Projects • 68 • : Zaphod58 -
DONALD J. TRUMP - TIME's Most Extraordinary Person of the Year 2024.
Mainstream News • 39 • : WeMustCare -
The Acronym Game .. Pt.4
General Chit Chat • 1012 • : FullHeathen -
USS Liberty - I had no idea. Candace Owen Interview
US Political Madness • 33 • : DEATHANDTRUTH