It looks like you're using an Ad Blocker.
Please white-list or disable AboveTopSecret.com in your ad-blocking tool.
Thank you.
Some features of ATS will be disabled while you continue to use an ad-blocker.

Ask any question you want about Physics
page: 318share:
a reply to: Arbitrageur
Two questions
What is that on his sleeve?
Will this experiment harm your ear, (in space)?
Two questions
What is that on his sleeve?
Will this experiment harm your ear, (in space)?
I didn't pay any attention to his sleeve but whatever it is I doubt it's a physics question.
originally posted by: Cauliflower
a reply to: Arbitrageur
Two questions
What is that on his sleeve?
Will this experiment harm your ear, (in space)?
I did notice he was hiding behind a tree so if the gun came in his direction it would hit the tree instead of him or his ear. There are no trees in space to hide behind, but there are a lot of different ways you could do this in space and some might hurt your ear and some might not. If you did it in the ISS I'm sure it would be painfully loud due to the confined space. If you didn't have an effective way to stop the bullet then your ears would hurt from decompression before you suffocated from all the air leaking out through the bullet hole. He said "don't do this at home" and that probably applies to the ISS also.

If you did it on the moon and jumped up when you pulled the trigger you might not hear a sound but if you just stood there some initial sound before the gun left the fixture would travel through the ground and your legs to your ears but it probably wouldn't hurt.
a reply to: Arbitrageur
Thanks! I thought maybe that was the new windows 11 logo or something on his sleeve.
Thanks! I thought maybe that was the new windows 11 logo or something on his sleeve.
originally posted by: ImaFungi
a reply to: delbertlarson
I am sorry but I do not want to look up your videos, I would prefer to ask general and simple questions that can be answered simply here, by the yourself the source.
Wow. Time goes by. I wanted to respond to this but I got very busy with many work related things. Here is my response to the above quote: 1) I took a great deal of time to write up papers for publication; 2) Then, my work got reviewed and further improved several times; 3) Then, after publication, and realizing I could further improve the presentation I put together videos with lots of pictures; so 4) That is why I really want them watched first before I get into a bunch of questions. It took me a real long time and effort to get things right, and once done, that is the place I would hope future conversations would start.
I have been planning for quite some time to put up some threads on my theories here. First up will be the ABC Preon Model. I hope it won't be too long before I get started. But it still might be months away. The aether model will be quite a while down the road. I would just pop up the videos for discussion, but the mods didn't like that so this takes quite a bit of work for me to convert things to text and then upload pictures.
Nearer term, I have a couple of questions coming for this thread. I have read every post on this thread since I got involved, and I find there are some real good answers here from time to time.
I see that the Higgs mass is now being advertised as 125.09 +/- 0.24 GeV. This result comes from a combined analysis, which can be found
here. The combined analysis comes from two separate signals for each of two detectors. The ATLAS two
photon signal has a fit to 126.02 +/- 0.51; the CMS two photon signal is fit to 124.70 +/- 0.34; the ATLAS Z-pair (four lepton) signal is fit to
124.51 +/- 0.52; and the CMS Z-pair (four lepton) signal is fit to 125.59 +/- 0.45. (All numbers in GeV.)
So my question is this: how can the combined result have such a low error range? It would seem that when you combine the four result sets, the range should be a lot larger than +/- 0.24 GeV, since the mean values of the individual signal analyses vary from 126.02 to 124.51, and there is error within all of the four that should spread out the uncertainty even further from that. I would expect the result to be something like 125.25 +/- 1, or maybe even 125.25 +/- 1.5, although clearly those are just "eyeball" estimates since I don't have the data.
I have read the paper linked to above, but it is not at all clear to me how they achieve such a precise result. The analysis is looking at a liklihood function, which appears different from just having data points from which you determine a mean and variance. I can see how they can use several experiments to further tighten certain experimental uncertainties concerning detector operation, but I don't see how that would reduce the variance of the data if much of the data is centered at 126, and much centered at 124.5.
Can someone eplain this?
So my question is this: how can the combined result have such a low error range? It would seem that when you combine the four result sets, the range should be a lot larger than +/- 0.24 GeV, since the mean values of the individual signal analyses vary from 126.02 to 124.51, and there is error within all of the four that should spread out the uncertainty even further from that. I would expect the result to be something like 125.25 +/- 1, or maybe even 125.25 +/- 1.5, although clearly those are just "eyeball" estimates since I don't have the data.
I have read the paper linked to above, but it is not at all clear to me how they achieve such a precise result. The analysis is looking at a liklihood function, which appears different from just having data points from which you determine a mean and variance. I can see how they can use several experiments to further tighten certain experimental uncertainties concerning detector operation, but I don't see how that would reduce the variance of the data if much of the data is centered at 126, and much centered at 124.5.
Can someone eplain this?
I can give you my best guess, but I'm not really sure if it answers your question or not nor am I sure if the approach is truly statistically valid.
originally posted by: delbertlarson
I see that the Higgs mass is now being advertised as 125.09 +/- 0.24 GeV. This result comes from a combined analysis, which can be found here. The combined analysis comes from two separate signals for each of two detectors. The ATLAS two photon signal has a fit to 126.02 +/- 0.51; the CMS two photon signal is fit to 124.70 +/- 0.34; the ATLAS Z-pair (four lepton) signal is fit to 124.51 +/- 0.52; and the CMS Z-pair (four lepton) signal is fit to 125.59 +/- 0.45. (All numbers in GeV.)
So my question is this: how can the combined result have such a low error range? It would seem that when you combine the four result sets, the range should be a lot larger than +/- 0.24 GeV, since the mean values of the individual signal analyses vary from 126.02 to 124.51, and there is error within all of the four that should spread out the uncertainty even further from that. I would expect the result to be something like 125.25 +/- 1, or maybe even 125.25 +/- 1.5, although clearly those are just "eyeball" estimates since I don't have the data.
I have read the paper linked to above, but it is not at all clear to me how they achieve such a precise result. The analysis is looking at a liklihood function, which appears different from just having data points from which you determine a mean and variance. I can see how they can use several experiments to further tighten certain experimental uncertainties concerning detector operation, but I don't see how that would reduce the variance of the data if much of the data is centered at 126, and much centered at 124.5.
Can someone eplain this?
If you look at figure 1, it doesn't show data centered at 126 nor 124.5, and reading the explanation of the figure it sounds like they presume both experiments are measuring the same thing and have fixed systematic uncertainties to their best-fit values:
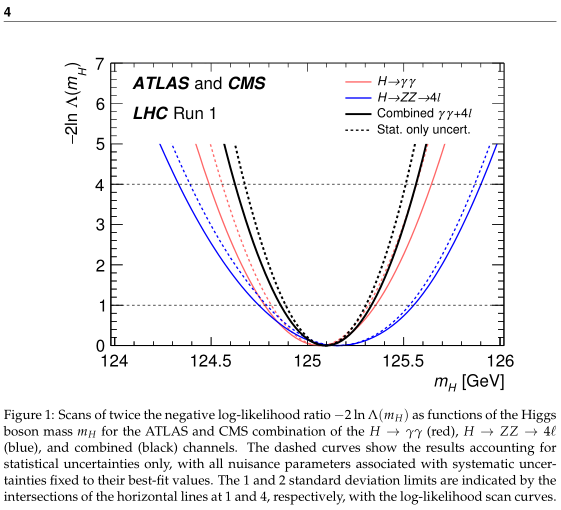
This gives me a pretty good idea of what they did, which is presume the difference between the 124.5 and the 126 as you put it was systematic.
The dashed curves show the results accounting for statistical uncertainties only, with all nuisance parameters associated with systematic uncertainties fixed to their best-fit values.
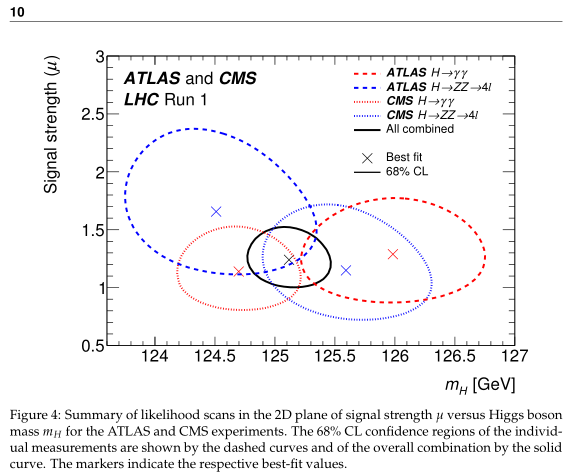
Figure 4 shows the data you talk about and I don't have much problem seeing how they got from figure 4 to figure 1 by assuming that systematic uncertainties account for the differences you mention.
edit on 201731 by Arbitrageur because: clarification
a reply to: Arbitrageur
Error analysis is always an interesting subject, and for delbertlarson I am quite surprised since iv often read threads about your scientific expertise... yet if I may be a little critical, while error analysis is a tough subject, you could apply the most basic method of combining values of different experiments outputting the same number and get something very very similar to what they present... hence my surprise that by eye you think the uncertainties have to be 5 times as large...
Lets see...
The four numbers
126.02+/-0.51 GeV
124.70+/-0.34 GeV
125.59+/-0.45 GeV
124.51+/-0.52 GeV
are made up of two sets, Diphoton and quadlepton, from two different experiments. This should using the simplest most relevant method that I would do, weighted mean, The value I calculate for it comes out as
Mean = Sum(value/error^2)/Sum(1/error^2)
Error = Sqrt(1/(Sum(1/error^2))
125.11 +/- 0.22 GeV compared to 125.09 +/- 0.24 GeV which is fairly close. I suspect the method used here is actually a frequentist analysis and includes uncertainties in a none trivial manner, their number is also more conservative than mine... so all looks very good, it is better to over estimate uncertainty than under in general.
Either way their method is a bit more than a simple weighted mean and takes into account confidence levels as shown in the plots above, the shape of those is what contributes and gives the slightly different mean value and error.
Error analysis is always an interesting subject, and for delbertlarson I am quite surprised since iv often read threads about your scientific expertise... yet if I may be a little critical, while error analysis is a tough subject, you could apply the most basic method of combining values of different experiments outputting the same number and get something very very similar to what they present... hence my surprise that by eye you think the uncertainties have to be 5 times as large...
Lets see...
The four numbers
126.02+/-0.51 GeV
124.70+/-0.34 GeV
125.59+/-0.45 GeV
124.51+/-0.52 GeV
are made up of two sets, Diphoton and quadlepton, from two different experiments. This should using the simplest most relevant method that I would do, weighted mean, The value I calculate for it comes out as
Mean = Sum(value/error^2)/Sum(1/error^2)
Error = Sqrt(1/(Sum(1/error^2))
125.11 +/- 0.22 GeV compared to 125.09 +/- 0.24 GeV which is fairly close. I suspect the method used here is actually a frequentist analysis and includes uncertainties in a none trivial manner, their number is also more conservative than mine... so all looks very good, it is better to over estimate uncertainty than under in general.
Either way their method is a bit more than a simple weighted mean and takes into account confidence levels as shown in the plots above, the shape of those is what contributes and gives the slightly different mean value and error.
edit on 2-3-2017 by ErosA433 because: (no reason given)
Thanks for your responses, Arbitrageur and ErosA433. Perhaps we can make more progress with a "straw man" to illustrate my difficulty in understanding
the result.
Let's say we have a Gaussian distribution of something, and for simplicity's sake for this argument let's say the mean is 0 and the standard deviation is 1. Then we run experiments. We could get results along the lines of 50 events between -2.5 and -1.5, 200 between -1.5 and -0.5, 500 between -0.5 and 0.5, 250 between 0.5 and 1.5, and 40 between 1.5 and 2.5. I am using values off the top of my head just to try to make a simple point, I could write a program to generate things that would be a better match to a Gaussian but I hope you see the idea. We could now look at each bin of events and say that clearly 100% of each bin's data falls within its own bin, and hence the one sigma error within each bin is conservatively about 0.2 (two and a half sigma will reach each side from the bin's mean, again this is just a straw man to illustrate the point: I know how sloppy and wrong this is.). If we do ErosA433's weighted average approach following this technique then we'd get a sigma of something less than 0.2 when we combine results, but we know in this case that the real sigma is 1.
Now clearly, the above "straw man" has differences from what is being reported from the LHC. In the "straw man", each bin would see a fall off within the bin as we get further from zero, whereas in the LHC I assume the data is something approaching a Gaussian around the individual means within each of their "bins". But here is the point that is similar between the "straw man" and LHC - if we have four or five different result sets whose means are separated by more than one of their internal standard deviations, how can we message things so as to claim an error so much smaller than the individual errors? I would think what one should do is find the overall mean and standard deviation based on the full data set, rather than combining means and errors of subsets of the data.
The only way I can see to arrive at a smaller error is by using one set of data to correct the other - that is, move the mean of each of the individual distributions to match some weighted mean of the total, and then the error might reduce due to the statistics. Although even that may not happen, since if you superimpose 20 Gaussians each with the same standard deviation on top of one another you will still have a Gaussian with the same standard deviation as the individual ones - you've just changed the amplitude.
By the way, here is how I guessed an "eyeball" error of a standard deviation of 1 to 1.5: In my mind's eye I just envisioned four Gaussians, each with a sigma of about 0.5, overlapped with a mean separations similar to the LHC results. Essentially just draw an ellipse that surrounds the four distorted ellipses in Figure 4. One side of each of the individual tails will overlap near the center, perhaps resulting in a denser distribution at the center of the total than at the individual centers, and the other side of the individual tails will extend beyond the drawn ellipse surrounding the four ellipses. Very simplistic and sloppy, I know, but I wouldn't think it would be that far off. Certainly not off all the way down to 0.24.
I look forward your further comments, Arbitrageur and ErosA433.
Let's say we have a Gaussian distribution of something, and for simplicity's sake for this argument let's say the mean is 0 and the standard deviation is 1. Then we run experiments. We could get results along the lines of 50 events between -2.5 and -1.5, 200 between -1.5 and -0.5, 500 between -0.5 and 0.5, 250 between 0.5 and 1.5, and 40 between 1.5 and 2.5. I am using values off the top of my head just to try to make a simple point, I could write a program to generate things that would be a better match to a Gaussian but I hope you see the idea. We could now look at each bin of events and say that clearly 100% of each bin's data falls within its own bin, and hence the one sigma error within each bin is conservatively about 0.2 (two and a half sigma will reach each side from the bin's mean, again this is just a straw man to illustrate the point: I know how sloppy and wrong this is.). If we do ErosA433's weighted average approach following this technique then we'd get a sigma of something less than 0.2 when we combine results, but we know in this case that the real sigma is 1.
Now clearly, the above "straw man" has differences from what is being reported from the LHC. In the "straw man", each bin would see a fall off within the bin as we get further from zero, whereas in the LHC I assume the data is something approaching a Gaussian around the individual means within each of their "bins". But here is the point that is similar between the "straw man" and LHC - if we have four or five different result sets whose means are separated by more than one of their internal standard deviations, how can we message things so as to claim an error so much smaller than the individual errors? I would think what one should do is find the overall mean and standard deviation based on the full data set, rather than combining means and errors of subsets of the data.
The only way I can see to arrive at a smaller error is by using one set of data to correct the other - that is, move the mean of each of the individual distributions to match some weighted mean of the total, and then the error might reduce due to the statistics. Although even that may not happen, since if you superimpose 20 Gaussians each with the same standard deviation on top of one another you will still have a Gaussian with the same standard deviation as the individual ones - you've just changed the amplitude.
By the way, here is how I guessed an "eyeball" error of a standard deviation of 1 to 1.5: In my mind's eye I just envisioned four Gaussians, each with a sigma of about 0.5, overlapped with a mean separations similar to the LHC results. Essentially just draw an ellipse that surrounds the four distorted ellipses in Figure 4. One side of each of the individual tails will overlap near the center, perhaps resulting in a denser distribution at the center of the total than at the individual centers, and the other side of the individual tails will extend beyond the drawn ellipse surrounding the four ellipses. Very simplistic and sloppy, I know, but I wouldn't think it would be that far off. Certainly not off all the way down to 0.24.
I look forward your further comments, Arbitrageur and ErosA433.
a reply to: delbertlarson
I don't follow your example well because I don't see any systematic uncertainty in it so let me give you an example with systematic uncertainty.
You have measurement device in your resistor making factory that checks the resistors' impedance, and let's say they are carbon resistors deposited on a ceramic base. These resistors have a negative thermal coefficient, i.e. the higher the temperature, the lower the resistivity.
At 7am it's relatively cool in the factory and let's say your 1000 ohm resistors are measuring an average of 1000 ohms with a standard deviation of 2 ohms.
By 3pm it's warmed up a lot in the factory (which is not air-conditioned in this example), and the resistors coming off the same manufacturing line are now measuring an average of 995 ohms with a standard deviation of 2 ohms.
Now in the real world what might happen a case like this is samples might be sent to an air-conditioned QC lab which checks them all at the same temperature to eliminate the temperature induced systematic uncertainty that made the resistance drop by an average of 5 ohms, but, it's not always that easy to get rid of systematic uncertainty and sometimes you might be stuck with some of it.
If we follow your suggestion to combine all the data, the standard deviation of combining the 7am data with the 3pm data is going to go way above 2 ohms when it really isn't way above 2 ohms, because the resistors may all actually have a standard deviation of 2 ohms and the 7am and 3pm runs may all actually have the same average resistance if measured at the same temperature. It's the temperature in the factory that causes systematic uncertainty between the 7am data and the 3pm data, and if you know this you can adjust your data accordingly and still presume that the standard deviation really is 2 ohms instead of some higher value that you would get with your method.
Now how well does this example translate to the ATLAS and CMS experiments? It does appear that they have some systematic uncertainties and the standard deviation changes somewhat from experiment to experiment but I feel there are some parallels with the resistor example where if you combine all the data you'll come up with an unrealistically high standard deviation. So instead of just lumping all data together, adjustments are made for systematic error and you get relatively small standard deviations this way which it looks to me like are probably supportable, at least I don't see any problem with this approach.
Now, the tricky part of this is whether your estimate of the actual value is correct or not and as Eros pointed out they used a fancier method than he showed to come up with 125.09. Is that really the correct value? I don't know but here's something else I look at. If all the Atlas data was centered at 124.5 and all the CMS data was centered at 126, I wouldn't know if for example all the systematic error might be in the CMS experiment and if 124.5 from ATLAS might be the true mean.
But that's not what happened, since BOTH the ATLAS and CMS data have runs that are above and below the 125.09, so considering that I don't see anything that alarms me about their approach.
I don't follow your example well because I don't see any systematic uncertainty in it so let me give you an example with systematic uncertainty.
You have measurement device in your resistor making factory that checks the resistors' impedance, and let's say they are carbon resistors deposited on a ceramic base. These resistors have a negative thermal coefficient, i.e. the higher the temperature, the lower the resistivity.
At 7am it's relatively cool in the factory and let's say your 1000 ohm resistors are measuring an average of 1000 ohms with a standard deviation of 2 ohms.
By 3pm it's warmed up a lot in the factory (which is not air-conditioned in this example), and the resistors coming off the same manufacturing line are now measuring an average of 995 ohms with a standard deviation of 2 ohms.
Now in the real world what might happen a case like this is samples might be sent to an air-conditioned QC lab which checks them all at the same temperature to eliminate the temperature induced systematic uncertainty that made the resistance drop by an average of 5 ohms, but, it's not always that easy to get rid of systematic uncertainty and sometimes you might be stuck with some of it.
If we follow your suggestion to combine all the data, the standard deviation of combining the 7am data with the 3pm data is going to go way above 2 ohms when it really isn't way above 2 ohms, because the resistors may all actually have a standard deviation of 2 ohms and the 7am and 3pm runs may all actually have the same average resistance if measured at the same temperature. It's the temperature in the factory that causes systematic uncertainty between the 7am data and the 3pm data, and if you know this you can adjust your data accordingly and still presume that the standard deviation really is 2 ohms instead of some higher value that you would get with your method.
Now how well does this example translate to the ATLAS and CMS experiments? It does appear that they have some systematic uncertainties and the standard deviation changes somewhat from experiment to experiment but I feel there are some parallels with the resistor example where if you combine all the data you'll come up with an unrealistically high standard deviation. So instead of just lumping all data together, adjustments are made for systematic error and you get relatively small standard deviations this way which it looks to me like are probably supportable, at least I don't see any problem with this approach.
Now, the tricky part of this is whether your estimate of the actual value is correct or not and as Eros pointed out they used a fancier method than he showed to come up with 125.09. Is that really the correct value? I don't know but here's something else I look at. If all the Atlas data was centered at 124.5 and all the CMS data was centered at 126, I wouldn't know if for example all the systematic error might be in the CMS experiment and if 124.5 from ATLAS might be the true mean.
But that's not what happened, since BOTH the ATLAS and CMS data have runs that are above and below the 125.09, so considering that I don't see anything that alarms me about their approach.
edit on 201732 by Arbitrageur because: clarification
I am also not sure how to interpret the question, since what you appear to be describing is binning errors which are and of themselves not quite the
same thing. The gaussian distribution is a typical shape for value with an error where the mean expectation value is its peak, and the sigma of the
gaussian representing the uncertainty.
There are other methods too, doing weighted uncertainties in which you may take the raw number under the 1 sigma area, sqrt it, and divide the full width by it. It all depends upon what you are trying to convey, and the meaning of the measurement. The point of taking a mean, is ALWAYS for the purpose of reducing uncertainty. Thus if you take a measurement 20 times, each of those measurements might have a fixed uncertainty, but the mean of those 20 measurements SHOULD have a lower uncertainty than each of the independent tests.
The gaussian is a representation of this, you perform a measurement, and you write down your number, each test you do you add a count to the corresponding bin... the shape you should get, is the gaussian. The uncertainty on each bin is a statistical uncertainty, which in most useful means is 1/N or 1/sqrtN... the reason for this? well again it is the weighting. There are statistical methods in which you may fit a gaussian to your data and extract the mean and sigma with uncertainties on those values also... the statistical uncertainty on each data point means that you pay closer attention to making your fit match the data with better certainty.
As for the Higgs fit... look at Arbitrageur's plot showing the circles. The black central cross is the best fit... the circle represents 1 sigma. When you eyeball if the mean fits the data, or there is something not right with the data is if that black circle either covers the data crosses, the data 1 sigma levels, or is way outside of them...
We find... only one result is in contention and that is the CMS diphoton. Which the 68% confidence limit JUST misses the central point. Is that bad? well no not really, because it is close and definitely within 2 sigma. What would be bad is say... if that point was way way way off the plot.
Parhaps thats not a great explanation, but is partly the thinking when looking at if errors look ok or not.
There are other methods too, doing weighted uncertainties in which you may take the raw number under the 1 sigma area, sqrt it, and divide the full width by it. It all depends upon what you are trying to convey, and the meaning of the measurement. The point of taking a mean, is ALWAYS for the purpose of reducing uncertainty. Thus if you take a measurement 20 times, each of those measurements might have a fixed uncertainty, but the mean of those 20 measurements SHOULD have a lower uncertainty than each of the independent tests.
The gaussian is a representation of this, you perform a measurement, and you write down your number, each test you do you add a count to the corresponding bin... the shape you should get, is the gaussian. The uncertainty on each bin is a statistical uncertainty, which in most useful means is 1/N or 1/sqrtN... the reason for this? well again it is the weighting. There are statistical methods in which you may fit a gaussian to your data and extract the mean and sigma with uncertainties on those values also... the statistical uncertainty on each data point means that you pay closer attention to making your fit match the data with better certainty.
As for the Higgs fit... look at Arbitrageur's plot showing the circles. The black central cross is the best fit... the circle represents 1 sigma. When you eyeball if the mean fits the data, or there is something not right with the data is if that black circle either covers the data crosses, the data 1 sigma levels, or is way outside of them...
We find... only one result is in contention and that is the CMS diphoton. Which the 68% confidence limit JUST misses the central point. Is that bad? well no not really, because it is close and definitely within 2 sigma. What would be bad is say... if that point was way way way off the plot.
Parhaps thats not a great explanation, but is partly the thinking when looking at if errors look ok or not.
a reply to: Arbitrageur
Thanks Arbitrageur, your example is a good one. In your example it is clear what the systematic error is. I also note that when you combine your results you still state the error remains 2 ohms, which I would agree with, not 2 divided by the square root of 2 ohms, which is what one would get if we take the formula helpfully provided by ErosA433. That it remains 2 ohms is similar to my example about multiple Gaussian result distributions. If each Gaussian set of results has the same standard deviation, and you just take more samples of something and achieve that same underlying Gaussian distribution of values, the standard deviation stays the same, you just have a larger amplitude of the Gaussian. Here both you and I are making the assumption that we are taking enough samples so that the statistical spread becomes small compared to the underlying standard deviation of the actual distribution.
Thanks, ErosA433 for stating that the error should decrease as we take more measurements. In some cases I would agree - but perhaps not this case. Where I would agree is if you have more than one possible discreet result. For instance, I did some analysis of polling for recent elections. There, I assumed you either vote one way or the other. I wrote a program assuming that there is a 50% chance that any individual votes one way, and 50% the other way. Then I put in a random number generator into the program to get results over a finite number of selections. As expected, when the sample size is small I get results far from 50-50. (For instance and of course, if the sample size is 1 you get 100% to 0%.) As I increased the sample size in my runs the results trended toward 50-50. And I have verified with this program that the standard deviation does drop as the square root of the number of tries. (No surprises there.)
In this case however we don't have multiple right answers with a random chance of finding them, other than the multiple answers within the natural width of the Higgs given by dEdt = hbar. With hbar = 6.6x10^16 eV-s, and a Higgs lifetime of 10^-22 s, we have a natural width of 6.6 MeV. The real result will give us a Gaussian distribution centered on the center of mass with a 6.6 MeV standard deviation, and when looking at data within that distribution more statistics will help us to see that Gaussian distribution flesh out more accurately. But the individual errors of the four data sets (ATLAS and CMS, each with di-photon or quad-lepton) are much greater than 6.6 MeV, they are more like 500 MeV, and so I come to the conclusion that the errors are almost completely systematic, both between and within the four data sets.
As for ATLAS and CMS, I will read through the paper once again. I will look for a reason to apply systematic corrections - which I did not see in my first read through. If we don't have a known reason to apply a systematic correction, I don't see how we have any good reason to apply them. And if we don't apply such corrections any measurement is as good as another. And if all measurements are equal, I believe we just have a big systematic error that encompasses all the results.
Now one thing that is important here is the role of background. And there, statistics very well might come into play. I'd like each of your comments on that. But even there I don't see any reason off-hand why one data set should be corrected toward another, or toward a weighted mean. It seems possible to me that one or another of the samples could be more right, and the others more wrong. It doesn't have to be the case that all of them are wrong in just such a way as to arrive at the weighted mean. In fact, I am very dubious that such a result would be the case. So I still don't see how one can claim the small error.
Also note that the systematic correction goes one way for ATLAS internally and the other way for CMS internally. (In ATLAS the two photon result measures a higher mass than the four lepton result, in CMS the four lepton result has the higher mass.) Now there may be a very good reason to apply systematic corrections in the way they do, but I didn't catch it in my first read through the paper. I would think it would be easier to understand how a reason corrects things in the same direction in both detectors rather than the opposite direction, but again, I'll be looking for such reasons the next time I read through the paper. Again, if there is no reason to correct it, and they are just using those weighted mean equations ErosA433 helpfully reminded us of, then I think the claim of such high accuracy is problematic. And the fact that they do appear to arrive very close to the weighed mean values is rather curious if they aren't actually using that as the basis for the claim.
It is now likely a good time to share why I found this issue. A few years ago the Higgs mass was announced at 126 GeV/c-squared. It took less than 20 minutes for me to find how the ABC Preon Model would be consistent with that. In the ABC Preon Model, these Higgs events should have the mass of the W plus half the mass of the Z, due to the preonic constituents of what are known as the Higgs, W and Z. However, a few years ago I also checked the top quark, and it's mass was a couple of GeV off from what the ABC Preon Model predicted. Within the last month I thought I'd take another look. I found that with the improved accuracy of recent W, Z and top mass measurements, the top mass was predicted by the ABC Preon Model to high accuracy. That, plus the 126 GeV/c-squared Higgs meant that all known data was consistent with the model, and there were now six quantitative predictions that used only three quantitative inputs, which I take as significant evidence for the model. (Note that the standard model does not make accurate predictions on masses prior to things being found.) So it was time to write up a second publication about this, as well as make numerous more quantitative predictions. But then I saw the 125.09 GeV/c-squared analysis with an error bar that puts the ABC Preon Model prediction off by three and a half standard deviations and that now throws doubt on one of the six quantitative predictions. Yet after that I saw that two of the four individual tests are indeed at 126. So the issue really becomes why the statistical corrections are made. If it is just a weighted mean, that is pretty meaningless. There must be reasons internal to the detector such as momentum scales and resolutions that cause one set of results to be systematically different - and that is the key to understanding this I believe.
I will post again once I get through the paper again, and in the meantime I look forward to any additional thoughts and comments. You are both very helpful to me, and I thank you.
Thanks Arbitrageur, your example is a good one. In your example it is clear what the systematic error is. I also note that when you combine your results you still state the error remains 2 ohms, which I would agree with, not 2 divided by the square root of 2 ohms, which is what one would get if we take the formula helpfully provided by ErosA433. That it remains 2 ohms is similar to my example about multiple Gaussian result distributions. If each Gaussian set of results has the same standard deviation, and you just take more samples of something and achieve that same underlying Gaussian distribution of values, the standard deviation stays the same, you just have a larger amplitude of the Gaussian. Here both you and I are making the assumption that we are taking enough samples so that the statistical spread becomes small compared to the underlying standard deviation of the actual distribution.
Thanks, ErosA433 for stating that the error should decrease as we take more measurements. In some cases I would agree - but perhaps not this case. Where I would agree is if you have more than one possible discreet result. For instance, I did some analysis of polling for recent elections. There, I assumed you either vote one way or the other. I wrote a program assuming that there is a 50% chance that any individual votes one way, and 50% the other way. Then I put in a random number generator into the program to get results over a finite number of selections. As expected, when the sample size is small I get results far from 50-50. (For instance and of course, if the sample size is 1 you get 100% to 0%.) As I increased the sample size in my runs the results trended toward 50-50. And I have verified with this program that the standard deviation does drop as the square root of the number of tries. (No surprises there.)
In this case however we don't have multiple right answers with a random chance of finding them, other than the multiple answers within the natural width of the Higgs given by dEdt = hbar. With hbar = 6.6x10^16 eV-s, and a Higgs lifetime of 10^-22 s, we have a natural width of 6.6 MeV. The real result will give us a Gaussian distribution centered on the center of mass with a 6.6 MeV standard deviation, and when looking at data within that distribution more statistics will help us to see that Gaussian distribution flesh out more accurately. But the individual errors of the four data sets (ATLAS and CMS, each with di-photon or quad-lepton) are much greater than 6.6 MeV, they are more like 500 MeV, and so I come to the conclusion that the errors are almost completely systematic, both between and within the four data sets.
As for ATLAS and CMS, I will read through the paper once again. I will look for a reason to apply systematic corrections - which I did not see in my first read through. If we don't have a known reason to apply a systematic correction, I don't see how we have any good reason to apply them. And if we don't apply such corrections any measurement is as good as another. And if all measurements are equal, I believe we just have a big systematic error that encompasses all the results.
Now one thing that is important here is the role of background. And there, statistics very well might come into play. I'd like each of your comments on that. But even there I don't see any reason off-hand why one data set should be corrected toward another, or toward a weighted mean. It seems possible to me that one or another of the samples could be more right, and the others more wrong. It doesn't have to be the case that all of them are wrong in just such a way as to arrive at the weighted mean. In fact, I am very dubious that such a result would be the case. So I still don't see how one can claim the small error.
Also note that the systematic correction goes one way for ATLAS internally and the other way for CMS internally. (In ATLAS the two photon result measures a higher mass than the four lepton result, in CMS the four lepton result has the higher mass.) Now there may be a very good reason to apply systematic corrections in the way they do, but I didn't catch it in my first read through the paper. I would think it would be easier to understand how a reason corrects things in the same direction in both detectors rather than the opposite direction, but again, I'll be looking for such reasons the next time I read through the paper. Again, if there is no reason to correct it, and they are just using those weighted mean equations ErosA433 helpfully reminded us of, then I think the claim of such high accuracy is problematic. And the fact that they do appear to arrive very close to the weighed mean values is rather curious if they aren't actually using that as the basis for the claim.
It is now likely a good time to share why I found this issue. A few years ago the Higgs mass was announced at 126 GeV/c-squared. It took less than 20 minutes for me to find how the ABC Preon Model would be consistent with that. In the ABC Preon Model, these Higgs events should have the mass of the W plus half the mass of the Z, due to the preonic constituents of what are known as the Higgs, W and Z. However, a few years ago I also checked the top quark, and it's mass was a couple of GeV off from what the ABC Preon Model predicted. Within the last month I thought I'd take another look. I found that with the improved accuracy of recent W, Z and top mass measurements, the top mass was predicted by the ABC Preon Model to high accuracy. That, plus the 126 GeV/c-squared Higgs meant that all known data was consistent with the model, and there were now six quantitative predictions that used only three quantitative inputs, which I take as significant evidence for the model. (Note that the standard model does not make accurate predictions on masses prior to things being found.) So it was time to write up a second publication about this, as well as make numerous more quantitative predictions. But then I saw the 125.09 GeV/c-squared analysis with an error bar that puts the ABC Preon Model prediction off by three and a half standard deviations and that now throws doubt on one of the six quantitative predictions. Yet after that I saw that two of the four individual tests are indeed at 126. So the issue really becomes why the statistical corrections are made. If it is just a weighted mean, that is pretty meaningless. There must be reasons internal to the detector such as momentum scales and resolutions that cause one set of results to be systematically different - and that is the key to understanding this I believe.
I will post again once I get through the paper again, and in the meantime I look forward to any additional thoughts and comments. You are both very helpful to me, and I thank you.
No problem - The minimum width of a peak will be in a round about way set by experimental resolution, event reconstruction and other effects such as
pileup event leakage and of course digitization.
There is then a width due to underlying science meaning that the particles produced will have some underlying energy that translates to the width in the same way that the proton proton collisions are not considered as two objects colliding. they are two composite objects made of 3 quarks each along with the possibility of valence quarks interacting, and such the momentum of the event is a bit complicated.
The result is valid at 125.09+/-0.24 GeV based upon the experimental measurements and the method of using the available datasets to give this number are not meaningless at all. It truly represents the current understanding of the higgs mass.
Why are they different? Probably it is systematics, one experiment is giving an invariant mass that is higher/lower than the other. This could be caused by many things, and even be related to which models they are using to reconstruct the events rather than hardware directly.
What would I expect if a 3rd experiment came along and provided another two results? Id expect them to be near to the current two within 1-2 sigma.
There is then a width due to underlying science meaning that the particles produced will have some underlying energy that translates to the width in the same way that the proton proton collisions are not considered as two objects colliding. they are two composite objects made of 3 quarks each along with the possibility of valence quarks interacting, and such the momentum of the event is a bit complicated.
The result is valid at 125.09+/-0.24 GeV based upon the experimental measurements and the method of using the available datasets to give this number are not meaningless at all. It truly represents the current understanding of the higgs mass.
Why are they different? Probably it is systematics, one experiment is giving an invariant mass that is higher/lower than the other. This could be caused by many things, and even be related to which models they are using to reconstruct the events rather than hardware directly.
What would I expect if a 3rd experiment came along and provided another two results? Id expect them to be near to the current two within 1-2 sigma.
a reply to: ErosA433
I read carefully through the paper again. I found this: "Since the weight of a channel in the final combination is determined by the inverse of the squared uncertainty, the approximate relative weights for the combined result are 19% (H -> gamma gamma) and 18% (H -> ZZ -> 4 leptons) for ATLAS and 40% (H -> gamma gamma) and 23% (H -> ZZ -> 4 leptons) for CMS." So this makes it pretty clear that the treatment is indeed in line with what you, ErosA433, have indicated. Also, as I read I specifically looked for a reason why the individual result sets are assumed to be systematically corrected to the overall mean, and I could find no reason.
As I understand it, what the weighted mean approach is essentially doing is 1) starting with the fact that we know we have a systematic error between the four data sets; then 2) correcting things by applying a systematic correction to all of the data within each individual data set to bring each data set to where it is now centered on the weighted mean; and 3) calculating a new error based on the corrected data. The corrected data now has more data than the individual sets, which reduces the error below what each individual data set originally had. I agree that assumption 1 is valid - we are measuring one value, so there must be a systematic error between the data sets somewhere. With your (ErosA433) additional comments I also see how step 3 can be valid, since we have many factors that can add in an additional random width to the measurement process beyond just the natural width, and such random widths can have statistical errors which can in turn be reduced by more statistics. However, I retain my belief that step 2 has no real merit in this case, as we really don't know how we should should adjust the individual data sets. We just know that some adjustment is needed somewhere. Any one of the experiments might be more right than the rest - we simply don't know. And that is why I still think the error is larger than advertised.
Also, I shouldn't have said the weighted mean approach is meaningless. Clearly, the best guess for the mass is the weighted mean of the results, and the error obtained by the approach has some meaning. Rather, my objection is that I think the error is an under-estimation, for the reason just described. I believe one should instead follow the more mundane and simple process and find the standard deviation: A) find the mean of all points; B) subtract that mean from each data point; C) square each result of the data so obtained; D) sum that data and divide by the number of data points; and E) take the square root. From what I understand, the weighted mean approach follows steps A through E for each experiment individually, and then adjusts each experimental data set by adding or subtracting a constant amount from each data point within a set such that the new mean for the set becomes the overall mean, and then the standard deviation of that combined data is what is evaluated to determine the combined error. (The adjustment essentially moves the individual data sets so that they all overlap on the overall mean.) It is the step of "adjusting" the data to the new mean that I object to. Because we really don't know which experimental data is the best. And if we don't "adjust" the data, we'll get a considerably larger error.
I read carefully through the paper again. I found this: "Since the weight of a channel in the final combination is determined by the inverse of the squared uncertainty, the approximate relative weights for the combined result are 19% (H -> gamma gamma) and 18% (H -> ZZ -> 4 leptons) for ATLAS and 40% (H -> gamma gamma) and 23% (H -> ZZ -> 4 leptons) for CMS." So this makes it pretty clear that the treatment is indeed in line with what you, ErosA433, have indicated. Also, as I read I specifically looked for a reason why the individual result sets are assumed to be systematically corrected to the overall mean, and I could find no reason.
As I understand it, what the weighted mean approach is essentially doing is 1) starting with the fact that we know we have a systematic error between the four data sets; then 2) correcting things by applying a systematic correction to all of the data within each individual data set to bring each data set to where it is now centered on the weighted mean; and 3) calculating a new error based on the corrected data. The corrected data now has more data than the individual sets, which reduces the error below what each individual data set originally had. I agree that assumption 1 is valid - we are measuring one value, so there must be a systematic error between the data sets somewhere. With your (ErosA433) additional comments I also see how step 3 can be valid, since we have many factors that can add in an additional random width to the measurement process beyond just the natural width, and such random widths can have statistical errors which can in turn be reduced by more statistics. However, I retain my belief that step 2 has no real merit in this case, as we really don't know how we should should adjust the individual data sets. We just know that some adjustment is needed somewhere. Any one of the experiments might be more right than the rest - we simply don't know. And that is why I still think the error is larger than advertised.
Also, I shouldn't have said the weighted mean approach is meaningless. Clearly, the best guess for the mass is the weighted mean of the results, and the error obtained by the approach has some meaning. Rather, my objection is that I think the error is an under-estimation, for the reason just described. I believe one should instead follow the more mundane and simple process and find the standard deviation: A) find the mean of all points; B) subtract that mean from each data point; C) square each result of the data so obtained; D) sum that data and divide by the number of data points; and E) take the square root. From what I understand, the weighted mean approach follows steps A through E for each experiment individually, and then adjusts each experimental data set by adding or subtracting a constant amount from each data point within a set such that the new mean for the set becomes the overall mean, and then the standard deviation of that combined data is what is evaluated to determine the combined error. (The adjustment essentially moves the individual data sets so that they all overlap on the overall mean.) It is the step of "adjusting" the data to the new mean that I object to. Because we really don't know which experimental data is the best. And if we don't "adjust" the data, we'll get a considerably larger error.
I see it has taken about five weeks to provide the background for this:
My ABC Preon Model has enough content that I've now posted 14 threads before I finally got to the above mass prediction. I hope you (Arbitrageur, ErosA433, and any other knowledgeable experts who may have checked in) can now clearly see where the above mass prediction comes from. Since that prediction ties back in to our earlier discussion I thought it reasonable to check in again here today.
I have four more threads to go with the material I presently have, I should then add an "all-in-one" thread, and then I will conclude my series. When it is done, I would appreciate any comments from those here who are expert in the particle physics field.
originally posted by: delbertlarson
a reply to: Arbitrageur
It is now likely a good time to share why I found this issue. A few years ago the Higgs mass was announced at 126 GeV/c-squared. It took less than 20 minutes for me to find how the ABC Preon Model would be consistent with that. In the ABC Preon Model, these Higgs events should have the mass of the W plus half the mass of the Z, due to the preonic constituents of what are known as the Higgs, W and Z.
My ABC Preon Model has enough content that I've now posted 14 threads before I finally got to the above mass prediction. I hope you (Arbitrageur, ErosA433, and any other knowledgeable experts who may have checked in) can now clearly see where the above mass prediction comes from. Since that prediction ties back in to our earlier discussion I thought it reasonable to check in again here today.
I have four more threads to go with the material I presently have, I should then add an "all-in-one" thread, and then I will conclude my series. When it is done, I would appreciate any comments from those here who are expert in the particle physics field.
Serious question.
How come my butt itches when its wet but not when its underwater.
How come my butt itches when its wet but not when its underwater.
edit on 9-4-2017 by BASSPLYR because: (no reason given)
Did you get a chance to read the threads on the ABC Preon Model? What do you think?
One question:
When moving towards the speed of light, mass becomes an issue. Can someone explain the locally witnessed effects of what this means? The ship breaks apart?
Part 2-
Assuming you have a Shrink ray for your spaceship, would this change anything about the mass problem gained as you accelerate? Is it like an infinite scale issue, or would it be substantially better to be small? As I understand you cannot reach lightspeed, but is mass an actual meaningful factor as to why?
When moving towards the speed of light, mass becomes an issue. Can someone explain the locally witnessed effects of what this means? The ship breaks apart?
Part 2-
Assuming you have a Shrink ray for your spaceship, would this change anything about the mass problem gained as you accelerate? Is it like an infinite scale issue, or would it be substantially better to be small? As I understand you cannot reach lightspeed, but is mass an actual meaningful factor as to why?
originally posted by: Mordekaiser
One question:
When moving towards the speed of light, mass becomes an issue. Can someone explain the locally witnessed effects of what this means? The ship breaks apart?
Part 2-
Assuming you have a Shrink ray for your spaceship, would this change anything about the mass problem gained as you accelerate? Is it like an infinite scale issue, or would it be substantially better to be small? As I understand you cannot reach lightspeed, but is mass an actual meaningful factor as to why?
Speed is relative. So nothing changes locally.
With mass in your case, you probably mean relativistic mass. You have to be careful when using it to avoid any confusion. It is probably better to use relativistic momentum and energy instead.
originally posted by: moebius
originally posted by: Mordekaiser
One question:
When moving towards the speed of light, mass becomes an issue. Can someone explain the locally witnessed effects of what this means? The ship breaks apart?
Part 2-
Assuming you have a Shrink ray for your spaceship, would this change anything about the mass problem gained as you accelerate? Is it like an infinite scale issue, or would it be substantially better to be small? As I understand you cannot reach lightspeed, but is mass an actual meaningful factor as to why?
Speed is relative. So nothing changes locally.
With mass in your case, you probably mean relativistic mass. You have to be careful when using it to avoid any confusion. It is probably better to use relativistic momentum and energy instead.
While moebius is correct, it might be helpful to say a few more words to answer your question. What happens in relativity as you speed up is that any clocks you have on your ship will appear to slow down, and your ship will appear to shrink in its direction of motion, as observed by those people you left behind. The ratio by which these things happen is called gamma, which is defined by gamma = sqrt[1/[1-(v^2/c^2)]]. So if you see your clock advance by 1 second, observers you left behind will show a clock advance of gamma seconds and they will say your clock is running slowly. Also, if you say your space ship is 100 feet long in the forward moving direction, observers you left behind will say it is 100 divided by gamma feet long and they will say it shrank. But for you, the whole time you accelerate, your ship is 100 feet long and your clocks appear to advance at the same rate. Since all your time pieces and measuring rods are affected in this way, you have no way of knowing if anything has changed by making measurements yourself. Everything on your ship appears to remain perfectly the same, you experience just a very smooth acceleration, and there is no fear of anything falling apart. The effects of length contraction and time dilation also work together so that no relative speed greater than that of light can be obtained.
Oddly, if you look back you will say that the observers you left behind are the ones that have shrunken rods and slowed clocks. Relativity tells us that neither you nor they are incorrect about what you observe, but rather that space and time are relative. Each set of observers have their own space and time and they just disagree about it. Essentially, relativity tells us that a portion of space gets converted into time, and a portion of time gets converted into space, whenever we accelerate*. The precursor theory to relativity said that there was a "preferred frame" wherein there were indeed correct measurements, but the overwhelming number of physicists have discarded that older way of looking at things. Note that both ways of looking at things lead to the same fundamental equations. The older way of looking at things is easier to understand since it doesn't involve space-time conversion* and it is also better able to explain certain quantum phenomena, yet relativity is far, far more popular presently.
There has been confusion over the years about mass. I believe that the best definition of mass is one that doesn't change at all when going to high velocity. Rather, what changes is the relationship between force and acceleration. Newton's law, F = dp/dt still holds, but now, rather than p = m*v, we have p = gamma*m*v, and that has led to people mistakenly combining the gamma with the m to say that there is a relativistic mass increase. But the problem with such an approach is that while F = gamma*m*a for perpendicular forces, F = gamma*gamma*gamma*m*a for longitudinal forces. So it is better to say that mass is just mass, and that what changes is the relationship between momentum, mass and velocity when one goes to high speeds.
*Note that in relativity there can be arguments about whether space and time really exist in the sense I describe here. The only thing relevant to relativity is empirical observation, so underlying concepts can lose any real meaning. Einstein followed a positivist (Machian) philosophy which abandons the need for underlying models for what nature "really is". You just have equations and experimental results. So it can be a bit dicey trying to explain things from a relativistic viewpoint.
new topics
-
Steering the Titantic from the Drydock.
US Political Madness: 14 minutes ago -
Paramilitary Leaks - John Williams
Whistle Blowers and Leaked Documents: 9 hours ago -
Some sausage, some chicken, some sauce, some onions and some garlic...and some peppers!
Food and Cooking: 10 hours ago -
Hearing more ambulances lately
Medical Issues & Conspiracies: 11 hours ago -
Los Angeles brush fires latest: 2 blazes threaten structures, prompt evacuations
Mainstream News: 11 hours ago -
House Passes Laken Riley Act
Mainstream News: 11 hours ago
top topics
-
House Passes Laken Riley Act
Mainstream News: 11 hours ago, 23 flags -
What Comes After January 20th
Mainstream News: 14 hours ago, 18 flags -
Los Angeles brush fires latest: 2 blazes threaten structures, prompt evacuations
Mainstream News: 11 hours ago, 7 flags -
Hearing more ambulances lately
Medical Issues & Conspiracies: 11 hours ago, 6 flags -
Let's Buy Greenland
General Chit Chat: 16 hours ago, 6 flags -
Those stupid GRAVITE commercials
Rant: 15 hours ago, 5 flags -
Paramilitary Leaks - John Williams
Whistle Blowers and Leaked Documents: 9 hours ago, 5 flags -
The more I think about it
General Chit Chat: 12 hours ago, 4 flags -
Canada as a state .. how would it work?
General Chit Chat: 14 hours ago, 4 flags -
Some sausage, some chicken, some sauce, some onions and some garlic...and some peppers!
Food and Cooking: 10 hours ago, 3 flags
active topics
-
Steering the Titantic from the Drydock.
US Political Madness • 0 • : CosmicFocus -
Meta Llama local AI system is scary good
Science & Technology • 48 • : ArMaP -
-@TH3WH17ERABB17- -Q- ---TIME TO SHOW THE WORLD--- -Part- --44--
Dissecting Disinformation • 3968 • : AianawaQ1320 -
Gravitic Propulsion--What IF the US and China Really Have it?
General Conspiracies • 34 • : Lazy88 -
Canada as a state .. how would it work?
General Chit Chat • 15 • : Freeborn -
Let's Buy Greenland
General Chit Chat • 16 • : Freeborn -
Post A Funny (T&C Friendly) Pic Part IV: The LOL awakens!
General Chit Chat • 8000 • : KrustyKrab -
Los Angeles brush fires latest: 2 blazes threaten structures, prompt evacuations
Mainstream News • 13 • : BeyondKnowledge3 -
House Passes Laken Riley Act
Mainstream News • 16 • : KrustyKrab -
Planned Civil War In Britain May Be Triggered Soon
Social Issues and Civil Unrest • 16 • : Freeborn