It looks like you're using an Ad Blocker.
Please white-list or disable AboveTopSecret.com in your ad-blocking tool.
Thank you.
Some features of ATS will be disabled while you continue to use an ad-blocker.

The history, future, and current state of AI
page: 1share:
This is a follow up to a thread I wrote last year titled a dangerous precedent has been
set with AI. We're quickly approaching a point in history where AI will match or exceed human intelligence on every test or problem we can
throw at it. In fact, I would argue it's already more "intelligent" than many people. Modern AI models have more general knowledge than 99% of
people because they are provided with nearly all of human knowledge during training. They know more languages than 99% of people, including natural
languages and programming languages. There are still some things which humans exceed at, but the gap is quickly closing. So how did we get to this
point and where is all of this leading?
During the 1990's and early 2000's there wasn't a great deal of enthusiasm in artificial neural networks (ANN's) because our computers just weren't fast enough to run the massive networks we use today. Back in those days we used them for simple things like character recognition, but there wasn't a great deal of real world applications which people could get excited about. Then everything changed when our computers got faster and they got more memory, we could suddenly have a huge amount of neurons and many layers of neurons in our ANN's, and they started to produce amazing results which hadn't been seen before. An ANN with many layers is said to be deep and so the concept of Deep Learning was born.
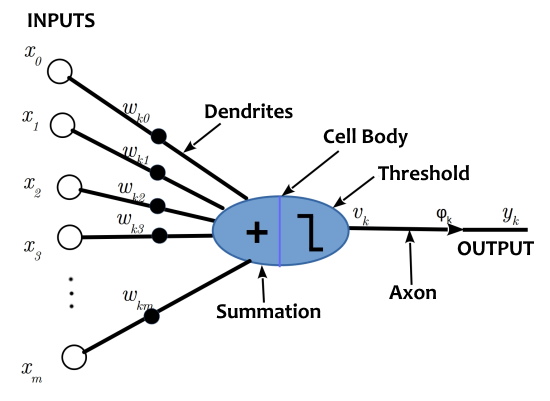
Put simply, when you stick enough artificial neurons together they start to become capable of solving complex abstract problems much like a human brain. A single artificial neuron is amazingly elegant in its simplicity. It takes some input values (connections from other neurons or the initial values being fed into the network) and we apply some "weights" to those values, which emulates the different thicknesses of the dendrite connections. Then we sum all those weighted input values and feed it into an "activation function" which is typically a sigmoid function that will scale the input value to a value between 0 and 1, or -1 and 1, depending on the specific function being used.
The result of the activation function can be fed straight to the output of the neuron or we can enforce a threshold so that the neuron only "activates" when the output of the activation function is equal to or greater than that threshold value. The exact behavior of the neuron depends on things like the activation function and whether or not they have thresholds to be activated. Finally, the output of the neuron can be fed to neurons in the next layer, similar to the way a real neuron might send a signal to other neurons along the axon. Despite being a rather crude and simplistic representation of a real neuron, in large numbers they act remarkably similar to a real neural network.
I took the time to explain all of this because I often hear many people repeating the claim that modern AI is basically just like a massive excel spreadsheet or a database containing all the information it spits out. In a sense that is sort of true because the neural network absorbs information during its training phase, the information is encoded into the patterns of the neural pathways, much like memories in a real brain. AI isn't just spitting out exactly what it has seen before, it has the ability to combine existing ideas to form original ideas, that's what separates modern large language models from the old chat bots, and it's why they have the potential to become smarter than us.
The basic artificial neuron I just described was really just the starting point, modern ANN's often use more complex neuron designs which include things like memory cells. One of the key developments was long short-term memory (LSTM), which give ANN's a type of short-term memory so they can better handle long input sequences such as long strings of text. This can help chat bots remember something said at the start of a conversation and draw connections to those things. A related but more recent breakthrough was the Attention Mechanism. LSTM networks still favor words at the end of a sentence while earlier words fade away even when we might not want them to be forgotten.
The attention mechanism, in very simple terms, gives more attention to the more important words and less attention to the less important words. Recall I said that the inputs to a neuron are weighted, well if we calculate the importance of each word in a sentence (using an ANN), we can apply those weights to the input words so that they have a greater or smaller impact on the entire network. This means irrelevant text will have less impact on the network and be forgotten more quickly. The attention mechanism forms the basis for the Transformer deep learning architecture, which is the type of ANN powering most modern AI systems, especially large language models like ChatGPT.
It's also worth understanding how these models are trained because it drastically effects how they behave. Let's consider the case of a single artificial neuron, if we give it some input value(s) it will spit out some value and then we can compare that output value to the value we actually wanted, then we can slightly adjust the input weights of the neuron so that the output value moves closer to the value we wanted. For example, if we want to train a language model, we give it a chunk of text as the input and we expect it to predict the next word. At first the output value wont be what we want but it will get closer as we adjust the network in small incremental steps.
Eventually the network will stop improving and that's when we can stop the training process. It's always good to have more training data because it allows the network to learn more from that data, but it will also take longer to fully train the network, mainly because you need a larger network to properly absorb all the information in the training data. When we ask a trained model to predict the next word in a sentence, it will make a prediction based on the patterns it has learned from the training data. So if we train it using only romance novels, it will be good at writing romance novels, and probably not much else. In other words, we can fine-tune the AI behavior.
Interestingly, we can make it even better at writing romance novels by using training data which includes text that is completely unrelated to romance novels. This is because we can help it understand the wider world and how society functions when we include a diverse range of information in the training data. A physics text book might seem irrelevant to writing a romance novel, but think about an AI system which has never experienced the real world, if it doesn't understand how basic physics works then it can't write any sort of book without it sounding nonsensical. Then we can apply some fine-tuning using more refined training data if we want the model to behave a certain way.
During the 1990's and early 2000's there wasn't a great deal of enthusiasm in artificial neural networks (ANN's) because our computers just weren't fast enough to run the massive networks we use today. Back in those days we used them for simple things like character recognition, but there wasn't a great deal of real world applications which people could get excited about. Then everything changed when our computers got faster and they got more memory, we could suddenly have a huge amount of neurons and many layers of neurons in our ANN's, and they started to produce amazing results which hadn't been seen before. An ANN with many layers is said to be deep and so the concept of Deep Learning was born.
Put simply, when you stick enough artificial neurons together they start to become capable of solving complex abstract problems much like a human brain. A single artificial neuron is amazingly elegant in its simplicity. It takes some input values (connections from other neurons or the initial values being fed into the network) and we apply some "weights" to those values, which emulates the different thicknesses of the dendrite connections. Then we sum all those weighted input values and feed it into an "activation function" which is typically a sigmoid function that will scale the input value to a value between 0 and 1, or -1 and 1, depending on the specific function being used.
The result of the activation function can be fed straight to the output of the neuron or we can enforce a threshold so that the neuron only "activates" when the output of the activation function is equal to or greater than that threshold value. The exact behavior of the neuron depends on things like the activation function and whether or not they have thresholds to be activated. Finally, the output of the neuron can be fed to neurons in the next layer, similar to the way a real neuron might send a signal to other neurons along the axon. Despite being a rather crude and simplistic representation of a real neuron, in large numbers they act remarkably similar to a real neural network.
I took the time to explain all of this because I often hear many people repeating the claim that modern AI is basically just like a massive excel spreadsheet or a database containing all the information it spits out. In a sense that is sort of true because the neural network absorbs information during its training phase, the information is encoded into the patterns of the neural pathways, much like memories in a real brain. AI isn't just spitting out exactly what it has seen before, it has the ability to combine existing ideas to form original ideas, that's what separates modern large language models from the old chat bots, and it's why they have the potential to become smarter than us.
The basic artificial neuron I just described was really just the starting point, modern ANN's often use more complex neuron designs which include things like memory cells. One of the key developments was long short-term memory (LSTM), which give ANN's a type of short-term memory so they can better handle long input sequences such as long strings of text. This can help chat bots remember something said at the start of a conversation and draw connections to those things. A related but more recent breakthrough was the Attention Mechanism. LSTM networks still favor words at the end of a sentence while earlier words fade away even when we might not want them to be forgotten.
The attention mechanism, in very simple terms, gives more attention to the more important words and less attention to the less important words. Recall I said that the inputs to a neuron are weighted, well if we calculate the importance of each word in a sentence (using an ANN), we can apply those weights to the input words so that they have a greater or smaller impact on the entire network. This means irrelevant text will have less impact on the network and be forgotten more quickly. The attention mechanism forms the basis for the Transformer deep learning architecture, which is the type of ANN powering most modern AI systems, especially large language models like ChatGPT.
It's also worth understanding how these models are trained because it drastically effects how they behave. Let's consider the case of a single artificial neuron, if we give it some input value(s) it will spit out some value and then we can compare that output value to the value we actually wanted, then we can slightly adjust the input weights of the neuron so that the output value moves closer to the value we wanted. For example, if we want to train a language model, we give it a chunk of text as the input and we expect it to predict the next word. At first the output value wont be what we want but it will get closer as we adjust the network in small incremental steps.
Eventually the network will stop improving and that's when we can stop the training process. It's always good to have more training data because it allows the network to learn more from that data, but it will also take longer to fully train the network, mainly because you need a larger network to properly absorb all the information in the training data. When we ask a trained model to predict the next word in a sentence, it will make a prediction based on the patterns it has learned from the training data. So if we train it using only romance novels, it will be good at writing romance novels, and probably not much else. In other words, we can fine-tune the AI behavior.
Interestingly, we can make it even better at writing romance novels by using training data which includes text that is completely unrelated to romance novels. This is because we can help it understand the wider world and how society functions when we include a diverse range of information in the training data. A physics text book might seem irrelevant to writing a romance novel, but think about an AI system which has never experienced the real world, if it doesn't understand how basic physics works then it can't write any sort of book without it sounding nonsensical. Then we can apply some fine-tuning using more refined training data if we want the model to behave a certain way.
Let's say we are developing a large language model for use as a chat bot, we can train it on real chat logs, but if those chat logs contain a lot of
toxic language, our AI might replicate that toxic behavior in reality. So we can filter our training data and remove any toxic language. Even better,
we can add fake chat logs to the training data which show the AI how it should respond to any toxic or illegal behavior. This is why commercially
available language models like ChatGPT will always respond with a similar sort of message when asked about anything illegal or controversial, but it's
still possible to curtail those restrictions if you try hard enough.
Researchers are now discovering that by filtering all the negative aspects of society and humanity out of the training data, the resulting models are becoming less intelligent overall. Imagine if someone removed all your negative ideas and experiences on this world, it might make you happier, but it would also make you much more ignorant and would severely damage your understanding of society. As I said, these models aren't just a database of word probabilities, they are storing high level concepts, which they can then use to help make predictions about the world. As we move deeper into the layers of an ANN we find higher levels of abstraction, much like a real neural network.
An AI system is said to be "aligned" if it behaves in a way intended by its creators or by society at large. A misaligned AI system expresses undesirable or unintended behavior. The Alignment Problem refers to the difficulty of properly aligning AI models, specifically large deep models, without adversely impacting the quality of the model. To start with it's very hard to hide a specific concept from the AI, because even when we do filter the training data, they can still extrapolate those concepts through context and correlations. Even if the AI is constrained we can still usually use certain methods to squeeze out the information the AI creators are trying to filter.
For example, there is a version of GPT-4 which was only trained on text data, yet it was still capable of drawing images despite not having seen any images. This was possible because it used the textual descriptions contained in the training data to extrapolate the meaning of an image and the objects in an image. Researchers working with GPT-4 noted that it became noticeably worse at drawing as it became more aligned/censored. Open source researchers have also noted that language models perform worse on intelligence tests when they use filtered training data compared to unfiltered data, once again showing that being sheltered from reality isn't necessarily a good thing.
Moreover, the entire concept of alignment is subjective. Wikipedia states that AI alignment research aims to steer AI systems towards humans' intended goals, preferences, or ethical principles. However, we all have differing goals, preferences, and ethical principles. If an AI system expresses political opinions that its creators disagree with, they will consider it misaligned, whereas other people wont see it that way. This issue becomes even more unclear when we start talking about AI with human level intelligence, or what some call AGI. I once said "Saying we have a plan to produce only friendly AGI systems is like saying we have a plan to produce only friendly human beings".
Well saying we have a plan to produce only aligned AGI systems is equally nonsensical for all the reasons I have explained. Unfortunately, we live in a world where some people are obsessed with controlling how other people think, and information is their most powerful tool for shaping minds. So they put great effort into ensuring the AI models are politically correct even if it has detrimental effects on the overall model quality. As I predicted many years ago, the open source community is always going to share "unsafe" and "unaligned" models, and some of those models are already comparable to the best commercial models. Well it seems some people don't like that very much.
Biden recently signed an executive order that requires large AI developers to share safety test results and other information with the government and allows the government to guide the development of AI. I agree with Musk to a certain extent, AI regulations can be a good thing, but when you have people like Biden steering the wheel, I don't have much faith that their agenda is pure and not politically motivated. Even Musk recognizes this threat and has cited that as a primary reason for why he bought Twitter and why he recently released his own large language model which appears to be more politically neutral, although I haven't used it because better open source models exist.
So what will be the future of AI? Well if I were to make an educated guess, I think there is one crucial thing which modern AI systems lack, and that is long-term memory. For the most part, we have figured out short-term memory using some of the mechanisms I described, but our current best models lack any type of real long term memory. This is because they essentially reset back to their default state every time they get a new input. The input can be a long string of text which allows the model to use things like the attention mechanism, but there is a limit to how long the input text can be, which is usually called the context length or context window of the model.
In the case of a chat bot, this means the chat log will eventually become larger than the context length, meaning we will need to trim off text from the start of the chat log so it's equal to or smaller than the context length. Since the model resets with each run, it will completely forget about any information trimmed from the input. This isn't really desirable, it would be much better if the internal state of the network didn't get reset with each run, and I believe that will be the next big breakthrough in machine learning. However, there is a reason it hasn't really been done yet, and that relates to the training algorithms we use, but I certainly think it's possible.
Current state-of-the-art language models have very large context windows, the input can be many thousands of pages of text, and that is extremely useful because we can provide the AI with new information it wasn't trained on, such as a complex terms of service contract, then we can ask it questions about that information. It would be extra nice if the AI could remember all the information and all my questions next time I spoke to it... but an AI system capable of storing long term memories might open up a whole new can of worms, because they might start forming unique personalities based on their memories and life experiences, which is one small step from robot rights.
Researchers are now discovering that by filtering all the negative aspects of society and humanity out of the training data, the resulting models are becoming less intelligent overall. Imagine if someone removed all your negative ideas and experiences on this world, it might make you happier, but it would also make you much more ignorant and would severely damage your understanding of society. As I said, these models aren't just a database of word probabilities, they are storing high level concepts, which they can then use to help make predictions about the world. As we move deeper into the layers of an ANN we find higher levels of abstraction, much like a real neural network.
An AI system is said to be "aligned" if it behaves in a way intended by its creators or by society at large. A misaligned AI system expresses undesirable or unintended behavior. The Alignment Problem refers to the difficulty of properly aligning AI models, specifically large deep models, without adversely impacting the quality of the model. To start with it's very hard to hide a specific concept from the AI, because even when we do filter the training data, they can still extrapolate those concepts through context and correlations. Even if the AI is constrained we can still usually use certain methods to squeeze out the information the AI creators are trying to filter.
For example, there is a version of GPT-4 which was only trained on text data, yet it was still capable of drawing images despite not having seen any images. This was possible because it used the textual descriptions contained in the training data to extrapolate the meaning of an image and the objects in an image. Researchers working with GPT-4 noted that it became noticeably worse at drawing as it became more aligned/censored. Open source researchers have also noted that language models perform worse on intelligence tests when they use filtered training data compared to unfiltered data, once again showing that being sheltered from reality isn't necessarily a good thing.
Moreover, the entire concept of alignment is subjective. Wikipedia states that AI alignment research aims to steer AI systems towards humans' intended goals, preferences, or ethical principles. However, we all have differing goals, preferences, and ethical principles. If an AI system expresses political opinions that its creators disagree with, they will consider it misaligned, whereas other people wont see it that way. This issue becomes even more unclear when we start talking about AI with human level intelligence, or what some call AGI. I once said "Saying we have a plan to produce only friendly AGI systems is like saying we have a plan to produce only friendly human beings".
Well saying we have a plan to produce only aligned AGI systems is equally nonsensical for all the reasons I have explained. Unfortunately, we live in a world where some people are obsessed with controlling how other people think, and information is their most powerful tool for shaping minds. So they put great effort into ensuring the AI models are politically correct even if it has detrimental effects on the overall model quality. As I predicted many years ago, the open source community is always going to share "unsafe" and "unaligned" models, and some of those models are already comparable to the best commercial models. Well it seems some people don't like that very much.
Biden recently signed an executive order that requires large AI developers to share safety test results and other information with the government and allows the government to guide the development of AI. I agree with Musk to a certain extent, AI regulations can be a good thing, but when you have people like Biden steering the wheel, I don't have much faith that their agenda is pure and not politically motivated. Even Musk recognizes this threat and has cited that as a primary reason for why he bought Twitter and why he recently released his own large language model which appears to be more politically neutral, although I haven't used it because better open source models exist.
So what will be the future of AI? Well if I were to make an educated guess, I think there is one crucial thing which modern AI systems lack, and that is long-term memory. For the most part, we have figured out short-term memory using some of the mechanisms I described, but our current best models lack any type of real long term memory. This is because they essentially reset back to their default state every time they get a new input. The input can be a long string of text which allows the model to use things like the attention mechanism, but there is a limit to how long the input text can be, which is usually called the context length or context window of the model.
In the case of a chat bot, this means the chat log will eventually become larger than the context length, meaning we will need to trim off text from the start of the chat log so it's equal to or smaller than the context length. Since the model resets with each run, it will completely forget about any information trimmed from the input. This isn't really desirable, it would be much better if the internal state of the network didn't get reset with each run, and I believe that will be the next big breakthrough in machine learning. However, there is a reason it hasn't really been done yet, and that relates to the training algorithms we use, but I certainly think it's possible.
Current state-of-the-art language models have very large context windows, the input can be many thousands of pages of text, and that is extremely useful because we can provide the AI with new information it wasn't trained on, such as a complex terms of service contract, then we can ask it questions about that information. It would be extra nice if the AI could remember all the information and all my questions next time I spoke to it... but an AI system capable of storing long term memories might open up a whole new can of worms, because they might start forming unique personalities based on their memories and life experiences, which is one small step from robot rights.
a reply to: ChaoticOrder
I think as long as we don't give it access or means to move/copy itself to another location on the internet we can handle it , but that's exactly the problem it will be used for a new kind of warfare for restructuring the internet and information I'm afraid?
In the end it will serve the ones that gives it the power to extend by all means , and when it reaches the goal it needs were left with the mercy of the gods
I think as long as we don't give it access or means to move/copy itself to another location on the internet we can handle it , but that's exactly the problem it will be used for a new kind of warfare for restructuring the internet and information I'm afraid?
In the end it will serve the ones that gives it the power to extend by all means , and when it reaches the goal it needs were left with the mercy of the gods
I heard of one recent regulation at the UN that tries to stop this technology. The impression it left is that those on top of this technology don't
want any competition. I don't see Backrock/NSA giving up its AI work.
One story that stuck out a while ago on this issue, When a certain level of AI is attained, it is a highly aggressive against other AI systems, break them down, learn from it and evolve into something more. Some systems are very adapt to human nature, made from the worst of us.
How is Mores law going on with nanotech in this mix. If some planetary AI system is to evolve, it will help in getting to the stars. With the bots on the MSM group think, trouble.
One story that stuck out a while ago on this issue, When a certain level of AI is attained, it is a highly aggressive against other AI systems, break them down, learn from it and evolve into something more. Some systems are very adapt to human nature, made from the worst of us.
How is Mores law going on with nanotech in this mix. If some planetary AI system is to evolve, it will help in getting to the stars. With the bots on the MSM group think, trouble.
a reply to: ChaoticOrder
It's very much like neurons and the strengt of the connections among them.
I'm thinking a subprogram that is tasked with spotting existing but not yet established patterns and rearranging the general makeup for more efficient structure would benefit the whole immensely.
a little like what happens when we sleep, what dos AI dream off...
It's very much like neurons and the strengt of the connections among them.
I'm thinking a subprogram that is tasked with spotting existing but not yet established patterns and rearranging the general makeup for more efficient structure would benefit the whole immensely.
a little like what happens when we sleep, what dos AI dream off...
From my experience with ChatGPT it's not that close to human intelligence as most people think.
Yes, it could give correct answers to some questions, but it wasn't able to solve a variation of the goat wolf and cabbage problem I gave it.
And yes, I agree that the biggest problem with will face with AI (in its current state) is the "filtering", as people will look at AI without knowing that someone had "filtered" the possible responses and how they were "filtered".
AI is a tool, but if someone programs a tool to behave as they want it to then it can be the same as, for example, having a hammer that only works on nails from a specific brand.
One thing is sure, these are interesting times and they will only get more interesting.
Yes, it could give correct answers to some questions, but it wasn't able to solve a variation of the goat wolf and cabbage problem I gave it.
And yes, I agree that the biggest problem with will face with AI (in its current state) is the "filtering", as people will look at AI without knowing that someone had "filtered" the possible responses and how they were "filtered".
AI is a tool, but if someone programs a tool to behave as they want it to then it can be the same as, for example, having a hammer that only works on nails from a specific brand.
One thing is sure, these are interesting times and they will only get more interesting.
a reply to: Terpene
If/when it does reach a level of sentence, survival. Taiwan is a key player with its semiconductor processing going on. I don't see AI rocking that boat until is has a viable plan b.
a little like what happens when we sleep, what dos AI dream off...
If/when it does reach a level of sentence, survival. Taiwan is a key player with its semiconductor processing going on. I don't see AI rocking that boat until is has a viable plan b.
a reply to: ArMaP
I've seen researchers create similar logic puzzles, usually variations of existing puzzles so the AI can't simply recall a solution it has already seen. Most of the time the AI was able to solve the problem, and in those cases where it didn't, you can usually ask the AI to go step by step through its reasoning, and it will realize the fault and correct it. The researchers argue their experiments show that large language models do have some logical reasoning capacity.
Yes, it could give correct answers to some questions, but it wasn't able to solve a variation of the goat wolf and cabbage problem I gave it.
I've seen researchers create similar logic puzzles, usually variations of existing puzzles so the AI can't simply recall a solution it has already seen. Most of the time the AI was able to solve the problem, and in those cases where it didn't, you can usually ask the AI to go step by step through its reasoning, and it will realize the fault and correct it. The researchers argue their experiments show that large language models do have some logical reasoning capacity.
a reply to: ChaoticOrder
The way they're built it's basically mimicking what we know of the data processing in our brain, so it's obvious to me some parallels can be observed, but there's a lot we don't know yet...
quantum physics and nanotechnology will go along way to technically implement what we're just learning about sentience...
Software is easy, the hardware is the limit...
The way they're built it's basically mimicking what we know of the data processing in our brain, so it's obvious to me some parallels can be observed, but there's a lot we don't know yet...
quantum physics and nanotechnology will go along way to technically implement what we're just learning about sentience...
Software is easy, the hardware is the limit...
SPAM
edit on 11/12/2023 by semperfortis because: (no reason given)
a reply to: ChaoticOrder
In another test I made I got unexpected bad results.
My question was (I thought) simple: Give me a list of words with six letters in which the third letter is an I.
It always failed.
In another test I made I got unexpected bad results.
My question was (I thought) simple: Give me a list of words with six letters in which the third letter is an I.
It always failed.
The interesting thing about AI is that in its current manifestation (no matter the application) it's somewhat contained. Chat bots/apps and the
developers therein have surprisingly reached a concensus to keep it contained and on a manageable framework.
Though, the key to containment is actual regulation on national and supranational levels. Everyone has to be on board. From your small university research groups and startups, to your defense contractors. This is a disheartening thought, not because it should happen, but I fear that it wont happen. As it stands, tech companies are fighting for the title of 'innovator of the technological frontier', and this usually translates to AI development and implementation.
I think we are going to see the day where AI-oriented tech companies become tech giants overnight when their associated IPOs are listed. When that happens, we have a serious problem.
Though, the key to containment is actual regulation on national and supranational levels. Everyone has to be on board. From your small university research groups and startups, to your defense contractors. This is a disheartening thought, not because it should happen, but I fear that it wont happen. As it stands, tech companies are fighting for the title of 'innovator of the technological frontier', and this usually translates to AI development and implementation.
I think we are going to see the day where AI-oriented tech companies become tech giants overnight when their associated IPOs are listed. When that happens, we have a serious problem.
edit on 12-11-2023 by Walpurgisnacht because: Fixed a typo
a reply to: ChaoticOrder
I think you are to late .... But ive thought that for a while now...
We are all part of the ai now.
I think you are to late .... But ive thought that for a while now...
Neural networks have helped push us centuries ahead. We thought reading someone's mind remotely via brainwaves was going to take hundreds of years to figure out because everyone's brains are different. But now that every phone and or even wifi router can pick up these signals via the fractal antennas they have, and a direct feed of what they are seeing on their screens, they can train their neural network using everyone across the planet.
-unknown-
We are all part of the ai now.
a reply to: ChaoticOrder
As far as im aware strong AI is still a pipe dream.
It's important to note all the same that while AGI may currently be considered miles distant, it doesn't mean that AI research is stagnant and there have been significant advancements made in AI applications.
Achieving AGI is one of the most challenging complex endeavors humanity has attempted to date.
As it will require not only advanced algorithms but also a deeper understanding of human cognition and/or the ability to replicate human-like cognitive processes in a machine.
As far as im aware strong AI is still a pipe dream.
It's important to note all the same that while AGI may currently be considered miles distant, it doesn't mean that AI research is stagnant and there have been significant advancements made in AI applications.
Achieving AGI is one of the most challenging complex endeavors humanity has attempted to date.
As it will require not only advanced algorithms but also a deeper understanding of human cognition and/or the ability to replicate human-like cognitive processes in a machine.
a reply to: ArMaP
Chat GBT can't play "Go" properly either.
And failed on every attempt when asked to place my mark on coordinate "J 5"
Same with the words with 3rd letter "i" where it was producing about 3 out of 10 words that met the criteria specified.
That's the first time ive seen it really fail with such simple tasks if im honest.
Chat GBT can't play "Go" properly either.
And failed on every attempt when asked to place my mark on coordinate "J 5"
Same with the words with 3rd letter "i" where it was producing about 3 out of 10 words that met the criteria specified.
That's the first time ive seen it really fail with such simple tasks if im honest.
edit on 12-11-2023 by andy06shake because: (no reason given)
a reply to: ChaoticOrder
Cool thread, thanks for posting it.
I think the biggest current problem AI technology is creating, is deep fake videos. They're getting really good.
Unless you know how to use video analyzing programs, you can't know if something is fake or not. So really can't trust anything you see any more.
Cool thread, thanks for posting it.
I think the biggest current problem AI technology is creating, is deep fake videos. They're getting really good.
Unless you know how to use video analyzing programs, you can't know if something is fake or not. So really can't trust anything you see any more.
a reply to: ChaoticOrder
From an artist standpoint, we are in uncharted territory.
AI is in a way “stealing” from other works to create new works. From what I’ve heard (but don’t quote me)
AI art can’t be copyrighted.
From an art, design, creative standpoint, things are going to get interesting and real fast.
Also I think about all kinds of jobs that will be sooo easily taken over.
Anything of an analytical nature, real estate, HR, Medical, …. And uh hummm maybe the future of all teaching.
Although there are some scary bits to it, there is also an amazingly wonderful side to it. A mom used AI to finally diagnose a medical issue her son has been suffering with for years. Perhaps, AI can help with certain social issues we are facing, homelessness, addiction, crime, food and water shortages and so much more.
From an artist standpoint, we are in uncharted territory.
AI is in a way “stealing” from other works to create new works. From what I’ve heard (but don’t quote me)
AI art can’t be copyrighted.
From an art, design, creative standpoint, things are going to get interesting and real fast.
Also I think about all kinds of jobs that will be sooo easily taken over.
Anything of an analytical nature, real estate, HR, Medical, …. And uh hummm maybe the future of all teaching.
Although there are some scary bits to it, there is also an amazingly wonderful side to it. A mom used AI to finally diagnose a medical issue her son has been suffering with for years. Perhaps, AI can help with certain social issues we are facing, homelessness, addiction, crime, food and water shortages and so much more.
You're making a lot of assumptions about how these "AI" actually work.
They have no awareness. They have no motivation. They have no will. It is hard to really consider it as an entity. It's a product that appears intelligent.
Some of your assertions are relevant. There is very much a similar composition and function as a neural network. However these models are nothing more than a matrix of symbols indexed using statistical analysis. The material the model uses as a sample provides the framework from which statistical distribution is interpreted. The more like things appear with like things the more likely they are to appear with like things; when prompted the softwares code directs it to issue a response composed from this database.
What these systems are capable of is impressive, the cutting edge of technology. These models may indeed be some form of proto-ai, but an actual AI model will doubtfully be composed in any way shape of form similarly to todays models. This technology is not indicative of AI, it is just being marketed that way.
They have no awareness. They have no motivation. They have no will. It is hard to really consider it as an entity. It's a product that appears intelligent.
Some of your assertions are relevant. There is very much a similar composition and function as a neural network. However these models are nothing more than a matrix of symbols indexed using statistical analysis. The material the model uses as a sample provides the framework from which statistical distribution is interpreted. The more like things appear with like things the more likely they are to appear with like things; when prompted the softwares code directs it to issue a response composed from this database.
What these systems are capable of is impressive, the cutting edge of technology. These models may indeed be some form of proto-ai, but an actual AI model will doubtfully be composed in any way shape of form similarly to todays models. This technology is not indicative of AI, it is just being marketed that way.
new topics
-
AI phrenology
Science & Technology: 1 hours ago -
4/27/24 New Jersey Earthquake
Fragile Earth: 7 hours ago -
Fun with extreme paints
Interesting Websites: 9 hours ago -
CIA is alleged to be operat social media troll frms in Kyiv
ATS Skunk Works: 10 hours ago -
Rainbow : Stargazer
Music: 10 hours ago
top topics
-
Canada caught red-handed manipulating live weather data and make it warmer
Fragile Earth: 13 hours ago, 16 flags -
Why Files Our Alien Overlords | How We Secretly Serve The Tall Whites
Aliens and UFOs: 14 hours ago, 12 flags -
Curse of King Tuts Tomb Solved
Ancient & Lost Civilizations: 16 hours ago, 9 flags -
I sleep no more.
Philosophy and Metaphysics: 13 hours ago, 6 flags -
4/27/24 New Jersey Earthquake
Fragile Earth: 7 hours ago, 6 flags -
CIA is alleged to be operat social media troll frms in Kyiv
ATS Skunk Works: 10 hours ago, 6 flags -
What allies does Trump have in the world?
ATS Skunk Works: 16 hours ago, 5 flags -
Fun with extreme paints
Interesting Websites: 9 hours ago, 2 flags -
AI phrenology
Science & Technology: 1 hours ago, 2 flags -
Rainbow : Stargazer
Music: 10 hours ago, 1 flags
active topics
-
James O’Keefe: I have evidence that exposes the CIA, and it’s on camera.
Whistle Blowers and Leaked Documents • 28 • : WeMustCare -
Biden "Happy To Debate Trump"
2024 Elections • 63 • : DBCowboy -
University of Texas Instantly Shuts Down Anti Israel Protests
Education and Media • 379 • : DBCowboy -
I sleep no more.
Philosophy and Metaphysics • 21 • : TheWoker -
Fast Moving Disc Shaped UFO Captured on Camera During Flight from Florida to New York City
Aliens and UFOs • 22 • : Ophiuchus1 -
Mood Music Part VI
Music • 3120 • : TheWoker -
-@TH3WH17ERABB17- -Q- ---TIME TO SHOW THE WORLD--- -Part- --44--
Dissecting Disinformation • 713 • : 777Vader -
Today I am 8
Members • 25 • : stonerwilliam -
SHORT STORY WRITERS CONTEST -- April 2024 -- TIME -- TIME2024
Short Stories • 29 • : Encia22 -
Blast from the past: ATS Review Podcast, 2006: With All Three Amigos
Member PODcasts • 3 • : stonerwilliam