It looks like you're using an Ad Blocker.
Please white-list or disable AboveTopSecret.com in your ad-blocking tool.
Thank you.
Some features of ATS will be disabled while you continue to use an ad-blocker.

John Titor Vs. Morey Haber (Text Comparison) - Hoaxhunter
page: 2share:
reply to post by Razimus
Ok, thanks (didn't think to check description, quite an obvious place to put them, sorry).
If I may ask, how did you compile text files from blogs?
Ok, thanks (didn't think to check description, quite an obvious place to put them, sorry).
If I may ask, how did you compile text files from blogs?
Originally posted by salainen
Interesting, the author has another thread on the same topic here.
He refers to himself in third person, quite interesting...
2 different videos, technically 2 different subjects, see the 40 minute video was too long, which is why I made this 6 minute video. If I went to the trouble of cutting down a video just for you guys, the least I can get is a new thread.
Originally posted by Razimus
Originally posted by salainen
Interesting, the author has another thread on the same topic here.
He refers to himself in third person, quite interesting...
2 different videos, technically 2 different subjects, see the 40 minute video was too long, which is why I made this 6 minute video. If I went to the trouble of cutting down a video just for you guys, the least I can get is a new thread.
Yes, I noticed that. The new thread was warranted, I know, I was just pointing out that you have another thread on the same topic which others may want to review.
John Titor is an interesting topic, but since its almost certainly a hoax, I wouldn't spend 40min watching, unless its almost pro quality. Might watch it later though.

Razimus,
Have you been able to find some specialists in the field to do a peer review on the material? That would go a long way in proving/disproving your findings.
Also, have you been in contact with Morey Haber....what does he have to say about this accusation?
Have you been able to find some specialists in the field to do a peer review on the material? That would go a long way in proving/disproving your findings.
Also, have you been in contact with Morey Haber....what does he have to say about this accusation?
Originally posted by Razimus
People make fun of the fact that I wasted my time, yet at the same time ask me to waste more of my time.
You shouldn't be taking this personally. It's feedback.
You seem very interested in getting a large audience but not in giving people what they want to warrant having that audience. (Or acknowledging that you're not the only one with an IQ)
ATS has a large number of varied persons who are resources for someone like you when you aren't dismissing them like school children. You asked a dozen people about the word 'infrastructure' ... what about the thousands of people on ATS? You want an expert, why didn't you ask ATS before starting??? We're awesome!
Originally posted by Razimus
I guess I have somewhat of a calculator in my head, that tells me it's mathematically very improbable for these 2 sets of text to be owned by anyone other than the same individual. And I guess the short attention span-prone don't have this 'calculator' in their head.
I have severe ADHD, I haven't lodged a casio calculator in my skull, but my gangnam style is pretty great.
The following is an example report only. Report may have sharp edges. Report is not suitable to eat. Please do not lick the report.
Why You Are Wrong: A report by Pinke
I am using three documents:
My datasets:
doc1.txt John Titor's text dump (Note, may contain google drive tags, but a small amount)
doc2.txt Haber's text dump (Note, may contain google drive tags, but a small amount)
doc2b.txt Haber's text dump with characters removed to reduce size (Should have deleted more)
example.txt krebsonsecurity blog, random selection of 113821 characters. (Should have got more)
My datasets were badly chosen and all the wrong sizes, and I lazily attempted to make them a similar size but couldn't be bothered; even then it shouldn't effect my findings.
My method:
I ran queries looking for varied sized n-grams (2 - 6 word phrases) and compared the results, including the uses of various terms within all docs. I also used the word list provided by Hoaxhunter.
Things I did:
This is a concordance plot of the n-gram great deal:

It's a favorite term by John Titor. It is completely absent from even the larger datasets. It is one of the few n-grams that can be used in enough contexts that I would expect to see it in more than one of the datasets if Titor was the author.
This is a concordance plot of the n-gram snapshot:
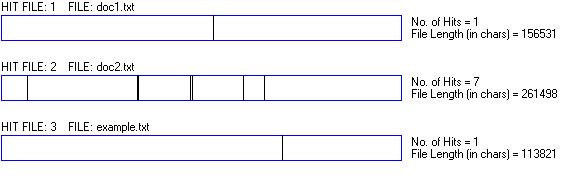
Despite the example dataset being smaller, it has an occurrence of this term. This is one of the alleged 'uncommon' words.
Concordance plot of the n-gram infrastructure:
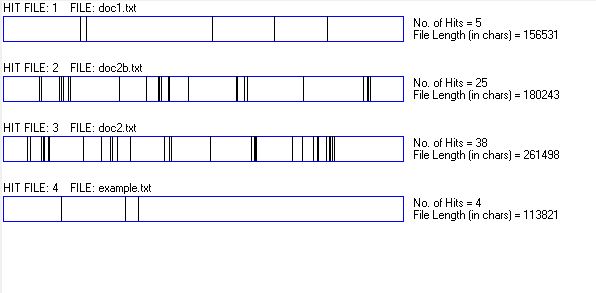
The term doesn't appear to be used any more or less in comparison to the other datasets, except the Morey Haber writings seems to be very much based around this topic in some respects.
Concordance plot of the n-gram inherent:

While this is a key part of the example text, it is not a key part of either of the other texts, but it does occur. It is not uncommon.
In fact, the vast majority of alleged 'uncommon' terms only show up in one instance between documents. The alleged six word terms do not even show up in the smaller datasets.
Overall Concordances
Sharing the number of exact phrases as seen in this comparative study is astounding
-- Hoaxhunter
The matches between the words and phrases of John Titor and Morey Haber is undeniable
-- Hoaxhunter
2 six word phrases out of over 23k unique possibilities (23966 approx)
5 five five word phrases out of over 24k unique possibilities (24523 approx)
61 four word phrases out of over 24k unique possibilities (24752 approx)
Over 400 three word phrases out of over 23k unique possibilities (23479 approx)
Some of the examples given by Hoaxhunter also overlap.
I can't agree with findings at this stage.
Conclusion:
Originally posted by sheepslayer247
Have you been able to find some specialists in the field to do a peer review on the material? That would go a long way in proving/disproving your findings.
There really is nothing to peer review.
The majority of terms of deep interest only present tiny numbers of times, or are deeply contextual. Haber uses 'for more information' 29 times to sell product, Titor uses it twice, but it is stated as 'relevant'. Unique terms which should present such as 'a great deal' are not addressed by Hoaxhunter unless I missed it?
The terms that do show up regularly such as 'based on' and 'the same' could easily be contextual. For example, if I ask you about the future, you may find yourself saying well this bit is 'the same' a lot.
This doesn't prove that the writer isn't Morey Haber, but the content provided by Hoaxhunter certainly doesn't prove that it is.
Probably best to ask an expert how to do this before starting next time (plagiarism software isn't the way to go). Then maybe an expert comes instead of a Pinke.
edit on 27-4-2013 by Pinke because: typos and such ; bit at end
I don't really get why the op comes under such heavy attack. I've seen the most worthless threads created with no effort given stars and flags
galore. The op obviously put some time into this, and if you disagree with it, then debate it without bashing the op for it. I've never thought too
much about the Titor thing, other than it's obvious BS. The op is clearly trying to shed light on who the hoaxer was, whether right or wrong, it's
commendable and not deserving of the rude posts it was greeted with.
Originally posted by notquiteright
I don't really get why the op comes under such heavy attack. I've seen the most worthless threads created with no effort given stars and flags galore. The op obviously put some time into this, and if you disagree with it, then debate it without bashing the op for it. I've never thought too much about the Titor thing, other than it's obvious BS. The op is clearly trying to shed light on who the hoaxer was, whether right or wrong, it's commendable and not deserving of the rude posts it was greeted with.
Has he been under heavy attack? He was certainly taking offence to everything, including my comments which I certainly meant no disrespect by. Everyone was just pointing out that the OP didn't have any controls for his testing, and thus its really hard to believe his claims on Titors identity. It is an interesting topic, but extraordinary claims need extraordinary evidence.
But sorry to OP if I was being too harsh, or personal. I didn't mean it, and all criticism was on the study, not you personally. I think you did a good job, and put lots of research into an interesting topic.
reply to post by salainen
Sorry, I didn't mean to jump on you, I guess I just felt like there was some negativity in there. Maybe it's just me.
Sorry, I didn't mean to jump on you, I guess I just felt like there was some negativity in there. Maybe it's just me.
reply to post by Razimus
I am (was) unbiased, until I noticed how much you feel the need to defend yourself while boasting about your superior knowledge of particular topics. The truth of the matter is, regardless of attention span, it’s up to the creator/producer/artist to get the “audience” interested quick enough to want view/listen/read anything longer than two minutes. It’s human nature to know what we like quite quickly. I suggest against the use of condescension to obtain support unless you prefer that type of demographic.
By the way, this is no attack on your OP.
It’s interesting enough to catch one’s eye…it’s keeping one’s ear that you may want to think about.
I am (was) unbiased, until I noticed how much you feel the need to defend yourself while boasting about your superior knowledge of particular topics. The truth of the matter is, regardless of attention span, it’s up to the creator/producer/artist to get the “audience” interested quick enough to want view/listen/read anything longer than two minutes. It’s human nature to know what we like quite quickly. I suggest against the use of condescension to obtain support unless you prefer that type of demographic.
By the way, this is no attack on your OP.
It’s interesting enough to catch one’s eye…it’s keeping one’s ear that you may want to think about.
new topics
-
The Effects of Electric Fields and Plasma on Plant Growth
Science & Technology: 23 minutes ago -
The daily fail trying to imply “it’s aliens”
The Gray Area: 7 hours ago -
Swarms of tiny 'ant-like' robots lift heavy objects and navigate obstacles
Science & Technology: 8 hours ago -
NYPD Chief Jeffrey Maddrey Resigns - Forced Officers to Give Sex for Overtime Pay and Favors.
Posse Comitatus: 10 hours ago
top topics
-
The Carpet Coating that Attacked the Environment
Medical Issues & Conspiracies: 14 hours ago, 13 flags -
Microplastics in your drinks
Medical Issues & Conspiracies: 15 hours ago, 5 flags -
NYPD Chief Jeffrey Maddrey Resigns - Forced Officers to Give Sex for Overtime Pay and Favors.
Posse Comitatus: 10 hours ago, 5 flags -
The daily fail trying to imply “it’s aliens”
The Gray Area: 7 hours ago, 3 flags -
Swarms of tiny 'ant-like' robots lift heavy objects and navigate obstacles
Science & Technology: 8 hours ago, 2 flags -
The Effects of Electric Fields and Plasma on Plant Growth
Science & Technology: 23 minutes ago, 0 flags
active topics
-
NYPD Chief Jeffrey Maddrey Resigns - Forced Officers to Give Sex for Overtime Pay and Favors.
Posse Comitatus • 5 • : andy06shake -
An Interesting Conversation with ChatGPT
Science & Technology • 34 • : randomuser2034 -
'Mass Casualty event' - Attack at Christmas market in Germany
Mainstream News • 142 • : SprocketUK -
The Effects of Electric Fields and Plasma on Plant Growth
Science & Technology • 0 • : ChaoticOrder -
The Carpet Coating that Attacked the Environment
Medical Issues & Conspiracies • 13 • : BeyondKnowledge3 -
Salvatore Pais confirms science in MH370 videos are real during live stream
General Conspiracies • 249 • : Skinnerbot -
The daily fail trying to imply “it’s aliens”
The Gray Area • 7 • : McGinty -
Microplastics in your drinks
Medical Issues & Conspiracies • 19 • : 38181 -
‘Something horrible’: Somerset pit reveals bronze age cannibalism
Ancient & Lost Civilizations • 12 • : McGinty -
Spiritual Solstice
Short Stories • 12 • : Naftalin