It looks like you're using an Ad Blocker.
Please white-list or disable AboveTopSecret.com in your ad-blocking tool.
Thank you.
Some features of ATS will be disabled while you continue to use an ad-blocker.

Archiving old UFO forum - html/file-name/linking issues
page: 14
share:
Although I don't post on ATS as frequently as I did a few years ago, I'm still continuing to archive and share UFO material. I've now helped make
over 400 sets of different UFO magazines/newsletters freely available online as searchable PDFs.
Anyway, I'm currently working on preserving and sharing a searchable archive of posts to the "Reality Uncovered" forum (with the blessing of one of the former owners of that forum, Ryan Dube).
Many pages of that forum (which used to be at realityuncovered.net) are preserved in the Wayback Machine archive, but that archive is not easily shared. I want to make pages of posts to that UFO forum available in one or two easily searched formats (including as PDF files, as I did with a Rendlesham UFO forum a few years ago).
After installing Ruby (a first for me...), I've used the free Wayback Machine Downloader available on Github at the link below to download over 7000 archived files from the realityuncovered.net website (most of those files being html files for individual pages of posts to that UFO forum):
github.com...
The Wayback Machine Downloader downloaded those files with filenames such as "viewtopic.php%3ff%3d19%26t%3d2165%26start%3d30".

Windows identified the period after "viewtopic" as indicating the rest of the file name is the file extension, but I have used the free Bulk Rename Tool at the link below to:
(1) rename all the files that didn't have a proper file extension so that the file extension is appended to the file name (by replacing .php with %2Ephp) and
(2) then added a new file extension of "html" for those files.
www.bulkrenameutility.co.uk...
Most of the files now open as html files and the text can be read. I could convert these to PDFs now and I'd get a considerable portion of what I wanted.
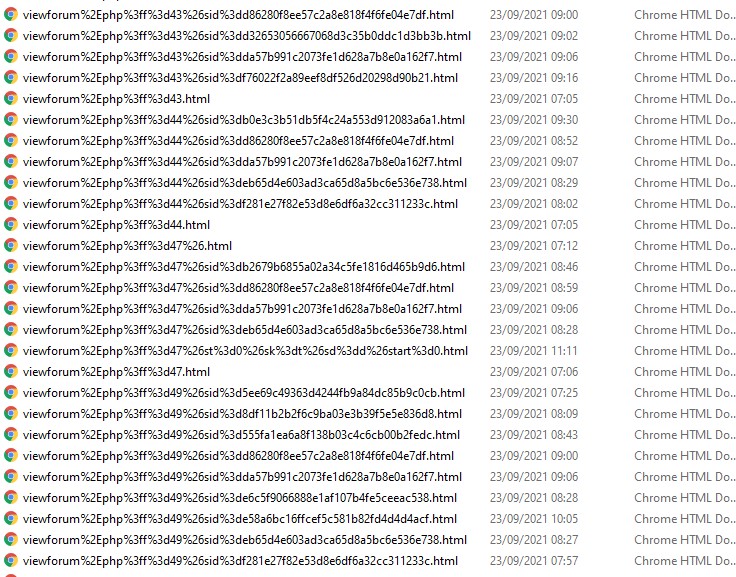
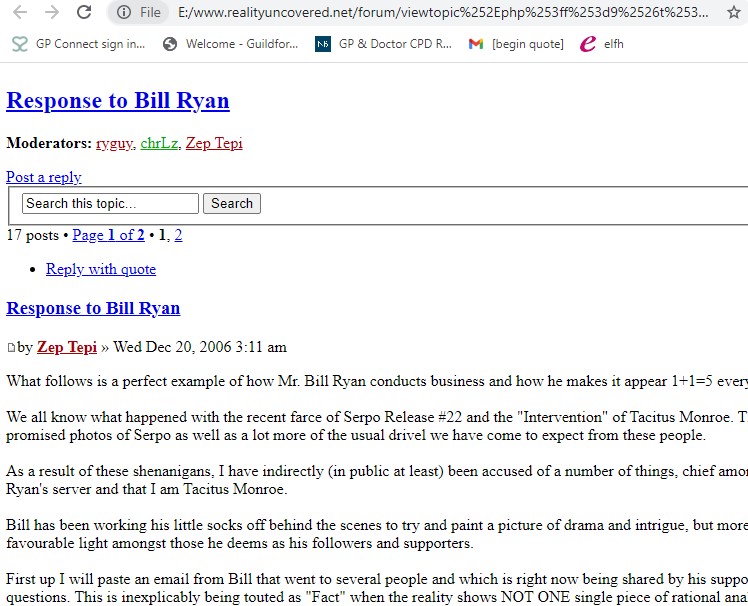
But I'd prefer to make some of the internal links work, e.g. when reading on page 1 of a thread, I'd like the link to page 2 to work.
The internal links in the html files downloaded by the Wayback Machine Downloader generally don't work - I think partly because some specify webpages in absolute terms (rather than relative ones) and also partly - I think - because they include characters such as ? and =, whereas the downloaded files include the escaped codes for those characters.
I've tried using Notepad++ "Find in Files" function to find and replace some of the parts of the links in all the html files with alternatives and managed to get a few of the links working.
Trial and error is - however - a bit time consuming and frustrating (not least because I'm sure there's a more elegant/simpler way to get this to work)
So, I know (or at least think...) that getting the internal links to work could eventually be done by using that find and replace method.
But I'm going to go nuts doing this on my own when I'm now really familiar with any of this technical stuff.
I'd welcome some input from those with a bit more technical knowledge than me.
Any thoughts?
Anyway, I'm currently working on preserving and sharing a searchable archive of posts to the "Reality Uncovered" forum (with the blessing of one of the former owners of that forum, Ryan Dube).
Many pages of that forum (which used to be at realityuncovered.net) are preserved in the Wayback Machine archive, but that archive is not easily shared. I want to make pages of posts to that UFO forum available in one or two easily searched formats (including as PDF files, as I did with a Rendlesham UFO forum a few years ago).
After installing Ruby (a first for me...), I've used the free Wayback Machine Downloader available on Github at the link below to download over 7000 archived files from the realityuncovered.net website (most of those files being html files for individual pages of posts to that UFO forum):
github.com...
The Wayback Machine Downloader downloaded those files with filenames such as "viewtopic.php%3ff%3d19%26t%3d2165%26start%3d30".
Windows identified the period after "viewtopic" as indicating the rest of the file name is the file extension, but I have used the free Bulk Rename Tool at the link below to:
(1) rename all the files that didn't have a proper file extension so that the file extension is appended to the file name (by replacing .php with %2Ephp) and
(2) then added a new file extension of "html" for those files.
www.bulkrenameutility.co.uk...
Most of the files now open as html files and the text can be read. I could convert these to PDFs now and I'd get a considerable portion of what I wanted.
But I'd prefer to make some of the internal links work, e.g. when reading on page 1 of a thread, I'd like the link to page 2 to work.
The internal links in the html files downloaded by the Wayback Machine Downloader generally don't work - I think partly because some specify webpages in absolute terms (rather than relative ones) and also partly - I think - because they include characters such as ? and =, whereas the downloaded files include the escaped codes for those characters.
I've tried using Notepad++ "Find in Files" function to find and replace some of the parts of the links in all the html files with alternatives and managed to get a few of the links working.
Trial and error is - however - a bit time consuming and frustrating (not least because I'm sure there's a more elegant/simpler way to get this to work)
So, I know (or at least think...) that getting the internal links to work could eventually be done by using that find and replace method.
But I'm going to go nuts doing this on my own when I'm now really familiar with any of this technical stuff.
I'd welcome some input from those with a bit more technical knowledge than me.
Any thoughts?
originally posted by: Macenroe82
Our friend Mr Rutkowski is sending me a bunch of old UFO magazines.
Once I receive them ill name the titles off to you and see if you already have them archived.
If not, then I can scan them and send them over to you.
That would be great.
I should be uploading more magazines soon, after dealing with sharing some defunct UFO websites/forums and potentially a new UFO database.
I'm currently going round and round in circles on this attempt to archive the RealityUncovered.net forum.
(I'll probably just convert the html pages to PDFs and share that. It will not work properly, but I want to move on to other projects soon).
edit on 24-9-2021 by IsaacKoi because: (no reason given)
parsing of archive information is usually the responsibility of the parser, not the archiver
imo, as long as you're keeping it archived, you have no further responsibility to resolve broken links therein, and any intelligent person trying to locate information will be more than capable of finding a way to follow a broken link.
Do you have access to Linux?
Ever heard of grep?
The literal tool you are looking for, is grep.
If you use grep, you can fix all these issues in about 5-10 minutes tops.
imo, as long as you're keeping it archived, you have no further responsibility to resolve broken links therein, and any intelligent person trying to locate information will be more than capable of finding a way to follow a broken link.
Do you have access to Linux?
Ever heard of grep?
The literal tool you are looking for, is grep.
If you use grep, you can fix all these issues in about 5-10 minutes tops.
originally posted by: Archivalist
Do you have access to Linux?
Ever heard of grep?
The literal tool you are looking for, is grep.
If you use grep, you can fix all these issues in about 5-10 minutes tops.
I've previously installed Linux on an old laptop, but not really used it.
I've heard of grep, but unfortunately that's as far my knowledge goes. (I'm a lawyer, with an interest in some technical stuff - but without much time to indulge that interest...).
While using grep to fix the problems may only take a few minutes, learning to use grep will presumably take quite a bit longer.
I think using the global find and replace "Find in Files" option in Notepad++ is about as far as I'm personally going to go on my own - and even that I'm hesitant about doing if my trial and error stab-in-the-dark experiments with exactly what needs to be replaced take much more of my time. (I've probably spent more than I should have on those experiments...)
edit on 24-9-2021 by IsaacKoi because: (no reason given)
Well, I've uploaded the forum part of RealityUncovered.net to the link below:
files.afu.se...
(I've only uploaded the html files so far. I'll keep trying for a bit longer to get more of the internal links working before producing any PDF copies of the "viewtopic..." files, which are the vast bulk of the text posted on that forum).
Here's a direct link to one of the thousands of "viewtopic..." files in the above folder:
files.afu.se... tml
files.afu.se...
(I've only uploaded the html files so far. I'll keep trying for a bit longer to get more of the internal links working before producing any PDF copies of the "viewtopic..." files, which are the vast bulk of the text posted on that forum).
Here's a direct link to one of the thousands of "viewtopic..." files in the above folder:
files.afu.se... tml
edit on 28-9-2021 by IsaacKoi because: (no reason given)
new topics
-
Israeli strikes on southern Gaza city of Rafah kill 22, mostly children, as US advances aid package
Middle East Issues: 3 hours ago -
Really Unexplained
Paranormal Studies: 8 hours ago -
The Vaccine Injured
Medical Issues & Conspiracies: 8 hours ago -
Leading Surgeon from Al-Shifa Hospital Dies in Israeli Custody
Middle East Issues: 11 hours ago
top topics
-
Zionists of ATS assemble
Political Issues: 14 hours ago, 12 flags -
Leading Surgeon from Al-Shifa Hospital Dies in Israeli Custody
Middle East Issues: 11 hours ago, 6 flags -
The Vaccine Injured
Medical Issues & Conspiracies: 8 hours ago, 4 flags -
Really Unexplained
Paranormal Studies: 8 hours ago, 4 flags -
Israeli strikes on southern Gaza city of Rafah kill 22, mostly children, as US advances aid package
Middle East Issues: 3 hours ago, 2 flags
4